
In the event you’ve labored with DeepSeek OCR, you already comprehend it was environment friendly at extracting textual content and compressing paperwork. The place it typically fell quick was studying order and layout-heavy pages, multi-column PDFs, dense tables, and combined content material nonetheless wanted cleanup. DeepSeek OCR 2 is DeepSeek’s reply to that hole. As a substitute of focusing solely on compression, this replace shifts consideration to how paperwork are literally learn. Early outcomes present cleaner construction, higher sequencing, and much fewer layout-related errors, particularly on real-world enterprise and technical paperwork. Let’s discover all the brand new options of DeepSekk OCR 2!
Key Options and Enhancements of DeepSeek OCR 2
- DeepEncoder V2 structure for logical studying order as an alternative of inflexible top-to-bottom scanning
- Improved structure understanding on complicated pages with multi-column textual content and dense tables
- Light-weight mannequin with 3 billion parameters, outperforming bigger fashions on structured paperwork
- Upgraded imaginative and prescient encoder, changing the older structure with a language-model–pushed design
- Larger benchmark efficiency, scoring 91.09 on OmniDocBench v1.5, a 3.73 proportion level enchancment over the earlier model
- Broad format assist, together with photos, PDFs, tables, and mathematical content material
- Open-source and fine-tunable, enabling customization for domain-specific use circumstances throughout industries
The DeepEncoder V2 Structure
Conventional OCR methods course of photos utilizing fastened grid-based scanning, which regularly limits studying order and structure understanding. DeepSeek OCR 2 adopts a special strategy primarily based on visible causal stream. The encoder first captures a worldwide view of the web page after which processes content material in a structured sequence utilizing learnable queries. This permits versatile dealing with of complicated layouts and improves studying order consistency.
Key architectural components embrace:
- Twin-attention design separating structure notion from studying order
- Visible tokens encoding full-page context and spatial construction
- Causal question tokens controlling sequential content material interpretation
- Language-model–pushed imaginative and prescient encoder offering order consciousness and spatial reference
- Reasoning-oriented encoder functioning past primary function extraction
- Decoder stage changing encoded representations into remaining textual content output
The architectural stream differs from the sooner model, which relied on a set, non-causal imaginative and prescient encoder. DeepEncoder V2 replaces this with a language-model–primarily based encoder and learnable causal queries, enabling international notion adopted by structured, sequential interpretation.
Efficiency Benchmarks
DeepSeek OCR 2 demonstrates robust benchmark efficiency. On OmniDocBench v1.5, it achieves a rating of 91.09, establishing a brand new cutting-edge in structured doc understanding. Probably the most important positive aspects seem in studying order accuracy, reflecting the effectiveness of the up to date structure.
In comparison with different vision-language fashions, DeepSeek OCR 2 preserves doc construction extra reliably than generic options akin to GPT-4 Imaginative and prescient. Its accuracy is akin to specialised industrial OCR methods, positioning it as a robust open-source different. Reported fine-tuning outcomes point out as much as an 86% discount in character error price for particular duties. Early evaluations additionally present improved dealing with of rotated textual content and sophisticated tables, supporting its suitability for difficult OCR workloads.
Additionally Learn: DeepSeek OCR vs Qwen-3 VL vs Mistral OCR: Which is the Greatest?
Easy methods to Entry and Use DeepSeek OCR 2?
You need to use DeepSeek OCR 2 with just a few traces of code. The mannequin is out there on the Hugging Face Hub. You will want a Python surroundings and a GPU with about 16 GB of VRAM.
However there’s a demo accessible at HuggingFace Areas for DeepSeek OCR 2 – Find it here.
Let’s take a look at the OCR 2.
Process 1: Dense Textual content and Desk-Heavy Paperwork

End result:
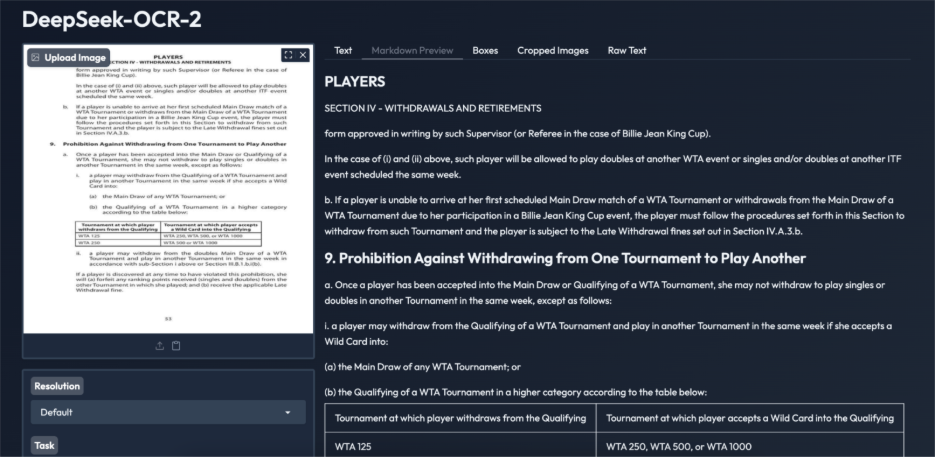
DeepSeek OCR 2 performs effectively on text-heavy scanned paperwork. The extracted textual content is correct, readable, and follows the proper studying order, even throughout dense paragraphs and numbered sections. Tables are transformed into structured HTML with constant ordering, a standard failure level for conventional OCR methods. Whereas minor formatting redundancies are current, total content material and structure stay intact. This instance demonstrates the mannequin’s reliability on complicated coverage and authorized paperwork, supporting document-level understanding past primary textual content extraction.
Process 2: Noisy, Low-Decision Photos

End result:
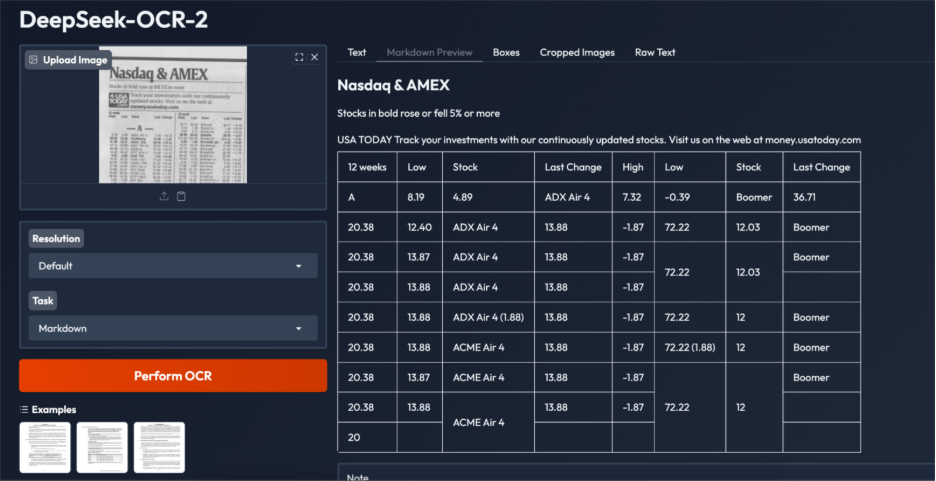
This instance highlights each the strengths and limitations of DeepSeek OCR 2 on extraordinarily noisy, low-resolution monetary tabular knowledge. The mannequin appropriately identifies key headings and supply textual content and acknowledges the content material as tabular, producing a table-based output relatively than plain textual content. Nonetheless, structural points stay, together with duplicated rows, irregular cell alignment, and occasional incorrect cell merging, seemingly on account of dense layouts, small font sizes, and low picture high quality.
Whereas most numerical values and labels are captured precisely, post-processing is required for manufacturing use. General, the outcomes point out robust structure intent recognition, with closely cluttered monetary tables remaining a difficult edge case.
When to Use DeepSeek OCR 2?
- Processing complicated paperwork akin to tutorial papers, technical documentation, and newspapers
- Changing scanned and digital paperwork into structured codecs, together with Markdown
- Extracting structured data from enterprise paperwork akin to invoices, contracts, and monetary statements
- Dealing with layout-intensive content material the place construction preservation is crucial
- Area-specific doc processing by means of fine-tuning for medical, authorized, or specialised terminology
- Privateness-sensitive workflows enabled by native, on-premise deployment
- Safe doc processing for presidency companies and enterprises with out cloud knowledge switch
- Integration into trendy AI and doc processing pipelines throughout industries
Additionally Learn: Prime 8 OCR Libraries in Python to Extract Textual content from Picture
Conclusion
DeepSeek OCR 2 represents a transparent step ahead in doc AI. The DeepEncoder V2 structure improves structure dealing with and studying order, addressing limitations seen in earlier OCR methods. The mannequin achieves excessive accuracy whereas remaining light-weight and cost-efficient. As a totally open-source system, it permits builders to construct doc understanding workflows with out reliance on proprietary APIs. This launch displays a broader shift in OCR from character-level extraction towards document-level interpretation, combining imaginative and prescient and language for extra structured and dependable processing of complicated paperwork.
Ceaselessly Requested Questions
A. It’s a vision-language mannequin that’s open-source. It’s an optical character recognition and doc understanding firm.
A. It really works with a particular structure by means of which it reads the paperwork within the human-like and logical sequence. This enhances precision in overlaying complicated plans.
A. Sure, it’s an open-source mannequin. You possibly can obtain and run it by yourself {hardware} free of charge.
A. You want a pc with a contemporary GPU. At the very least 16 GB of VRAM is really useful for good efficiency.
A. It’s primarily made to accommodate printed or digital textual content. Different particular fashions could also be simpler in writing complicated handwriting.
![]()
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.


