
The success of machine studying pipelines relies on function engineering as their important basis. The 2 strongest strategies for dealing with time collection information are lag options and rolling options, in response to your superior methods. The power to make use of these methods will improve your mannequin efficiency for gross sales forecasting, inventory worth prediction, and demand planning duties.
This information explains lag and rolling options by exhibiting their significance and offering Python implementation strategies and potential implementation challenges by working code examples.
What’s Characteristic Engineering in Time Collection?
Time collection function engineering creates new enter variables by the method of remodeling uncooked temporal information into options that allow machine studying fashions to detect temporal patterns extra successfully. Time collection information differs from static datasets as a result of it maintains a sequential construction, which requires observers to grasp that previous observations influence what’s going to come subsequent.
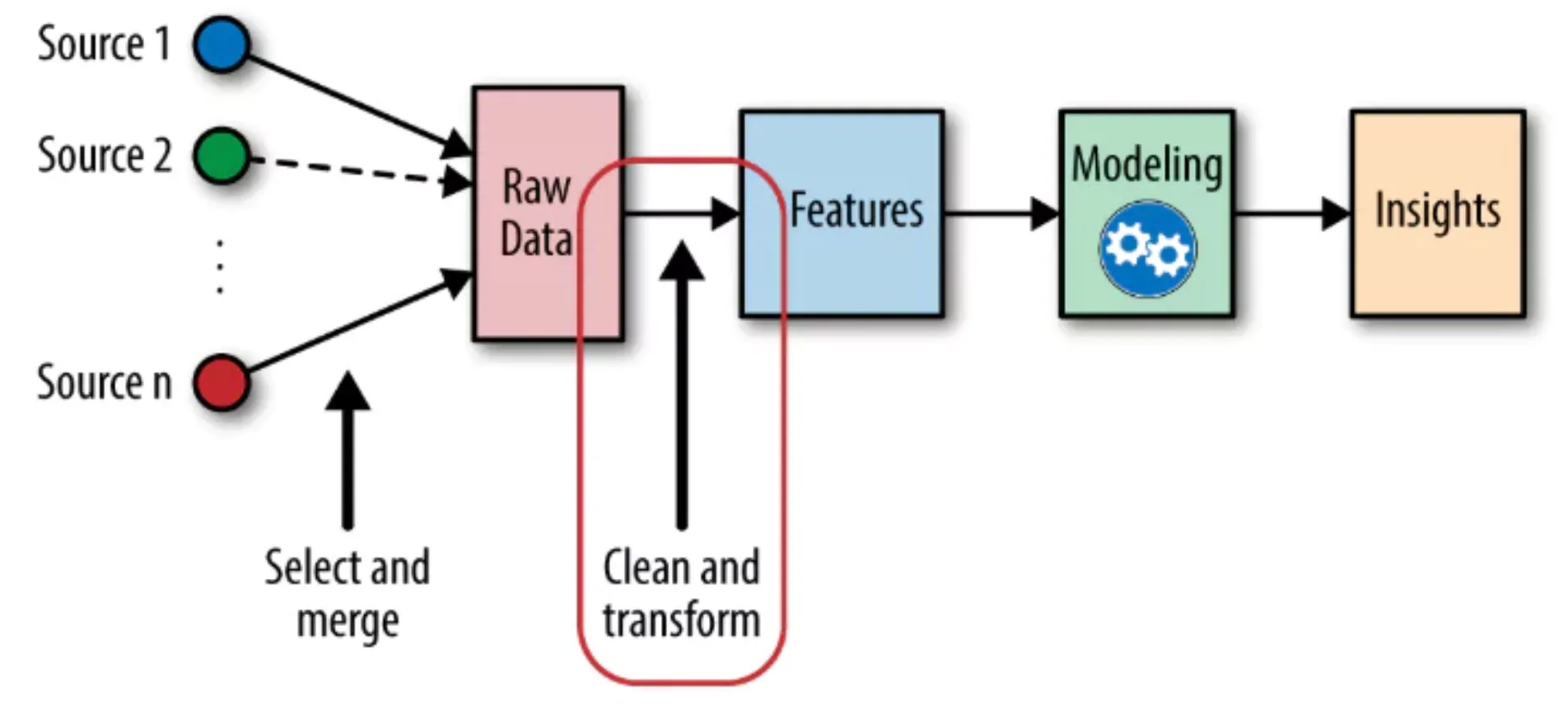
The traditional machine studying fashions XGBoost, LightGBM, and Random Forests lack built-in capabilities to course of time. The system requires particular indicators that want to point out previous occasions that occurred earlier than. The implementation of lag options along with rolling options serves this goal.
What Are Lag Options?
A lag function is just a previous worth of a variable that has been shifted ahead in time till it matches the present information level. The gross sales prediction for right now relies on three completely different gross sales data sources, which embody yesterday’s gross sales information and each seven-day and thirty-day gross sales information.

Why Lag Options Matter
- They characterize the connection between completely different time intervals when a variable exhibits its previous values.
- The strategy permits seasonal and cyclical patterns to be encoded without having sophisticated transformations.
- The strategy gives easy computation along with clear outcomes.
- The system works with all machine studying fashions that use tree buildings and linear strategies.
Implementing LAG Options in Python
import pandas as pd
import numpy as np
# Create a pattern time collection dataset
np.random.seed(42)
dates = pd.date_range(begin="2024-01-01", intervals=15, freq='D')
gross sales = [200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285]
df = pd.DataFrame({'date': dates, 'gross sales': gross sales})
df.set_index('date', inplace=True)
# Create lag options
df['lag_1'] = df['sales'].shift(1)
df['lag_3'] = df['sales'].shift(3)
df['lag_7'] = df['sales'].shift(7)
print(df.head(12))Output:
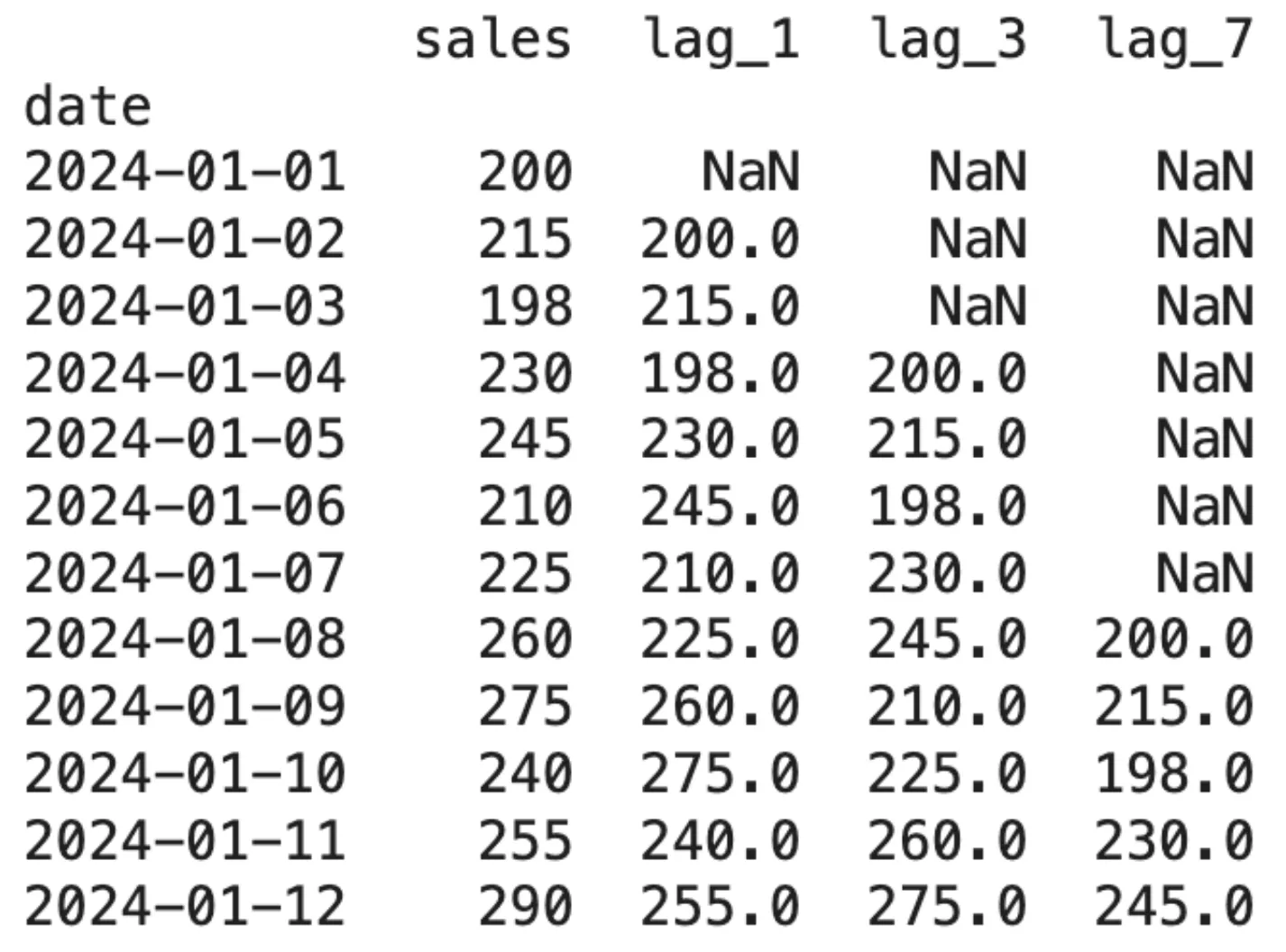
The preliminary look of NaN values demonstrates a type of information loss that happens due to lagging. This issue turns into essential for figuring out the variety of lags to be created.
Selecting the Proper Lag Values
The choice course of for optimum lags calls for scientific strategies that get rid of random choice as an choice. The next strategies have proven profitable leads to follow:
- The information of the area helps lots, like Weekly gross sales information? Add lags at 7, 14, 28 days. Hourly power information? Strive 24 to 48 hours.
- Autocorrelation Operate ACF allows customers to find out which lags present vital hyperlinks to their goal variable by its statistical detection methodology.
- The mannequin will determine which lags maintain the very best significance after you full the coaching process.
What Are Rolling (Window) Options?
The rolling options operate as window options that function by shifting by time to calculate variable portions. The system gives you with aggregated statistics, which embody imply, median, normal deviation, minimal, and most values for the final N intervals as a substitute of exhibiting you a single previous worth.

Why Rolling Options Matter?
The next options present glorious capabilities to carry out their designated duties:
- The method eliminates noise components whereas it reveals the basic development patterns.
- The system allows customers to watch short-term worth fluctuations that happen inside particular time intervals.
- The system allows customers to watch short-term worth fluctuations that happen inside particular time intervals.
- The system identifies uncommon behaviour when current values transfer away from the established rolling common.
The next aggregations set up their presence as normal follow in rolling home windows:
- The commonest methodology of development smoothing makes use of a rolling imply as its major methodology.
- The rolling normal deviation operate calculates the diploma of variability that exists inside a specified time window.
- The rolling minimal and most capabilities determine the very best and lowest values that happen throughout an outlined time interval/interval.
- The rolling median operate gives correct outcomes for information that features outliers and displays excessive ranges of noise.
- The rolling sum operate helps monitor whole quantity or whole rely throughout time.
Implementing Rolling Options in Python
import pandas as pd
import numpy as np
np.random.seed(42)
dates = pd.date_range(begin="2024-01-01", intervals=15, freq='D')
gross sales = [200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285]
df = pd.DataFrame({'date': dates, 'gross sales': gross sales})
df.set_index('date', inplace=True)
# Rolling options with window dimension of three and seven
df['roll_mean_3'] = df['sales'].shift(1).rolling(window=3).imply()
df['roll_std_3'] = df['sales'].shift(1).rolling(window=3).std()
df['roll_max_3'] = df['sales'].shift(1).rolling(window=3).max()
df['roll_mean_7'] = df['sales'].shift(1).rolling(window=7).imply()
print(df.spherical(2))Output:
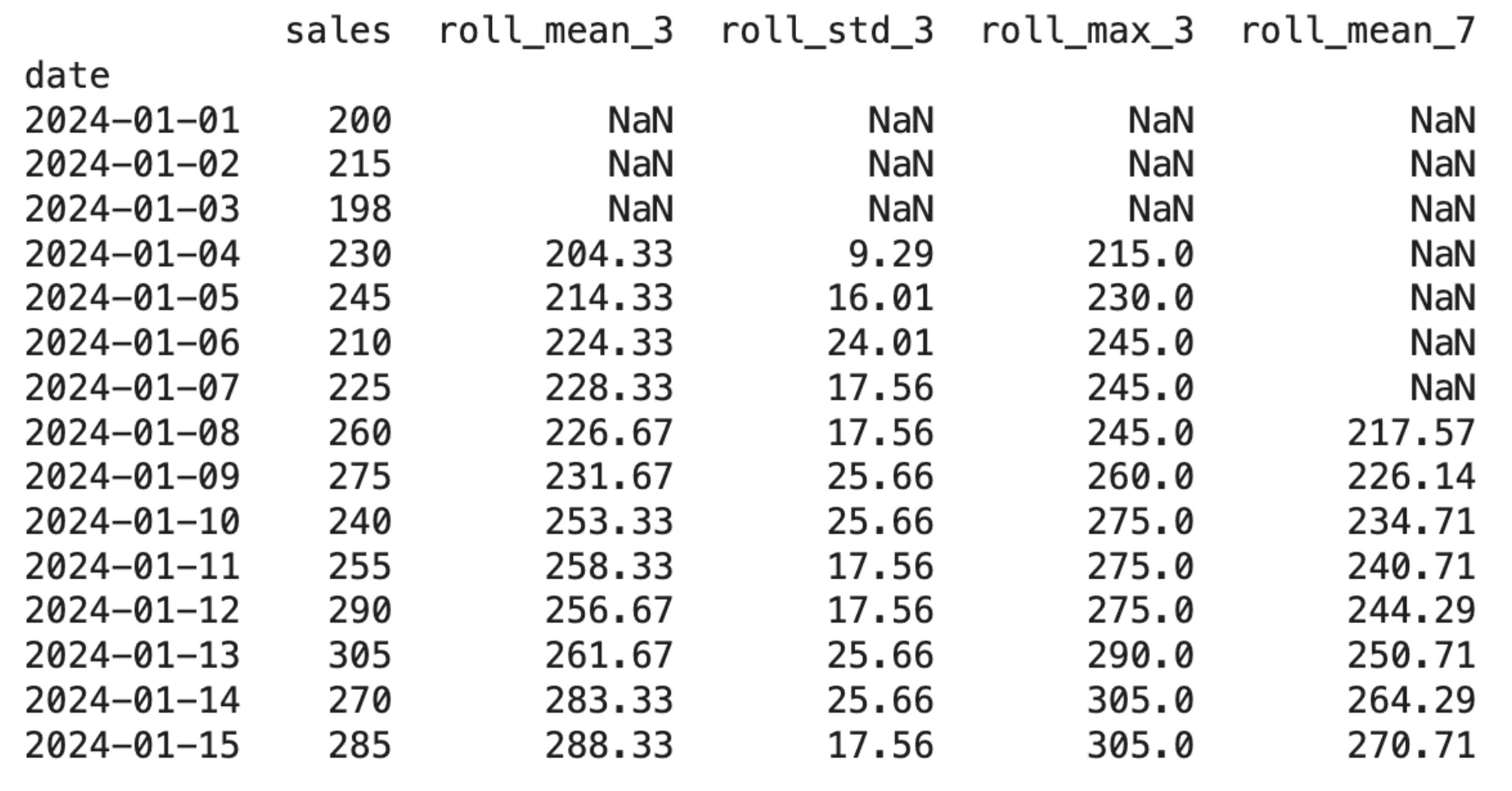
The .shift(1) operate should be executed earlier than the .rolling() operate as a result of it creates a significant connection between each capabilities. The system wants this mechanism as a result of it’s going to create rolling calculations that rely completely on historic information with out utilizing any present information.
Combining Lag and Rolling Options: A Manufacturing-Prepared Instance
In precise machine studying time collection workflows, researchers create their very own hybrid function set, which incorporates each lag options and rolling options. We offer you an entire function engineering operate, which you should utilize for any venture.
import pandas as pd
import numpy as np
def create_time_features(df, target_col, lags=[1, 3, 7], home windows=[3, 7]):
"""
Create lag and rolling options for time collection ML.
Parameters:
df : DataFrame with datetime index
target_col : Title of the goal column
lags : Record of lag intervals
home windows : Record of rolling window sizes
Returns:
DataFrame with new options
"""
df = df.copy()
# Lag options
for lag in lags:
df[f'lag_{lag}'] = df[target_col].shift(lag)
# Rolling options (shift by 1 to keep away from leakage)
for window in home windows:
shifted = df[target_col].shift(1)
df[f'roll_mean_{window}'] = shifted.rolling(window).imply()
df[f'roll_std_{window}'] = shifted.rolling(window).std()
df[f'roll_max_{window}'] = shifted.rolling(window).max()
df[f'roll_min_{window}'] = shifted.rolling(window).min()
return df.dropna() # Drop rows with NaN from lag/rolling
# Pattern utilization
np.random.seed(0)
dates = pd.date_range('2024-01-01', intervals=60, freq='D')
gross sales = 200 + np.cumsum(np.random.randn(60) * 5)
df = pd.DataFrame({'gross sales': gross sales}, index=dates)
df_features = create_time_features(df, 'gross sales', lags=[1, 3, 7], home windows=[3, 7])
print(f"Unique form: {df.form}")
print(f"Engineered form: {df_features.form}")
print(f"nFeature columns:n{checklist(df_features.columns)}")
print(f"nFirst few rows:n{df_features.head(3).spherical(2)}")Output:

Frequent Errors and The way to Keep away from Them
Essentially the most extreme error in time collection function engineering happens when information leakage, which reveals upcoming information to testing options, results in deceptive mannequin efficiency.
Key errors to be careful for:
- The method requires a .shift(1) command earlier than beginning the .rolling() operate. The present commentary will change into a part of the rolling window as a result of rolling requires the primary commentary to be shifted.
- Knowledge loss happens by the addition of lags as a result of every lag creates NaN rows. The 100-row dataset will lose 30% of its information as a result of 30 lags require 30 NaN rows to be created.
- The method requires separate window dimension experiments as a result of completely different traits want completely different window sizes. The method requires testing brief home windows, which vary from 3 to five, and lengthy home windows, which vary from 14 to 30.
- The manufacturing atmosphere requires you to compute rolling and lag options from precise historic information, which you’ll use throughout inference time as a substitute of utilizing your coaching information.
When to Use Lag vs. Rolling Options
| Use Case | Advisable Options |
|---|---|
| Sturdy autocorrelation in information | Lag options (lag-1, lag-7) |
| Noisy sign, want smoothing | Rolling imply |
| Seasonal patterns (weekly) | Lag-7, lag-14, lag-28 |
| Pattern detection | Rolling imply over lengthy home windows |
| Anomaly detection | Deviation from rolling imply |
| Capturing variability / danger | Rolling normal deviation, rolling vary |
Conclusion
The time collection machine studying infrastructure makes use of lag options and rolling options as its important parts. The 2 strategies set up a pathway from unprocessed sequential information to the organized information format that machine studying fashions require for his or her coaching course of. The strategies change into the very best influence issue for forecasting accuracy when customers execute them with exact information dealing with and window choice strategies, and their contextual understanding of the particular area.
The very best half? They supply clear explanations that require minimal computing assets and performance with any machine studying mannequin. These options will profit you no matter whether or not you utilize XGBoost for demand forecasting, LSTM for anomaly detection, or linear regression for baseline fashions.
![]()
Gen AI Intern at Analytics Vidhya
Division of Laptop Science, Vellore Institute of Know-how, Vellore, India
I’m at present working as a Gen AI Intern at Analytics Vidhya, the place I contribute to revolutionary AI-driven options that empower companies to leverage information successfully. As a final-year Laptop Science pupil at Vellore Institute of Know-how, I carry a stable basis in software program growth, information analytics, and machine studying to my position.
Be happy to attach with me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.


