
Proper now, at this time, you possibly can spend $14,000 and purchase a humanoid robotic.
There isn’t a security certification reviewed, no standardized take a look at protocol verified. You get a machine able to bodily pressure and real-time autonomous decision-making. And the frameworks for validating its conduct are nonetheless catching as much as what it might probably do.
That’s not a criticism of the engineers constructing these techniques. The intelligence facet of robotics is advancing at a tempo that genuinely deserves the thrill it will get: higher notion, extra strong locomotion, sooner inference, and tighter management loops.
However right here’s the query I preserve coming again to: Because the management structure of those techniques evolves from easy teleoperation all the way in which to totally autonomous reinforcement studying, are our testing methodologies and security validation processes evolving with them?
I don’t suppose they’re. Not but. And I believe that hole is value speaking about, to not gradual the business down, however to assist it scale responsibly.
Two analysis papers I’ve labored on just lately have formed how I take into consideration this. One proposes a framework for classifying robotic intelligence by its underlying management structure. The opposite examines how software program security threat evaluation must evolve for AI-driven techniques.
Collectively, they level towards one thing the business more and more wants: a testing philosophy that scales alongside autonomy. One the place formal security ensures exchange test-case enumeration on the highest ranges, and the place adversarial robustness analysis turns into as routine as useful testing.
First, a map of the place we’re
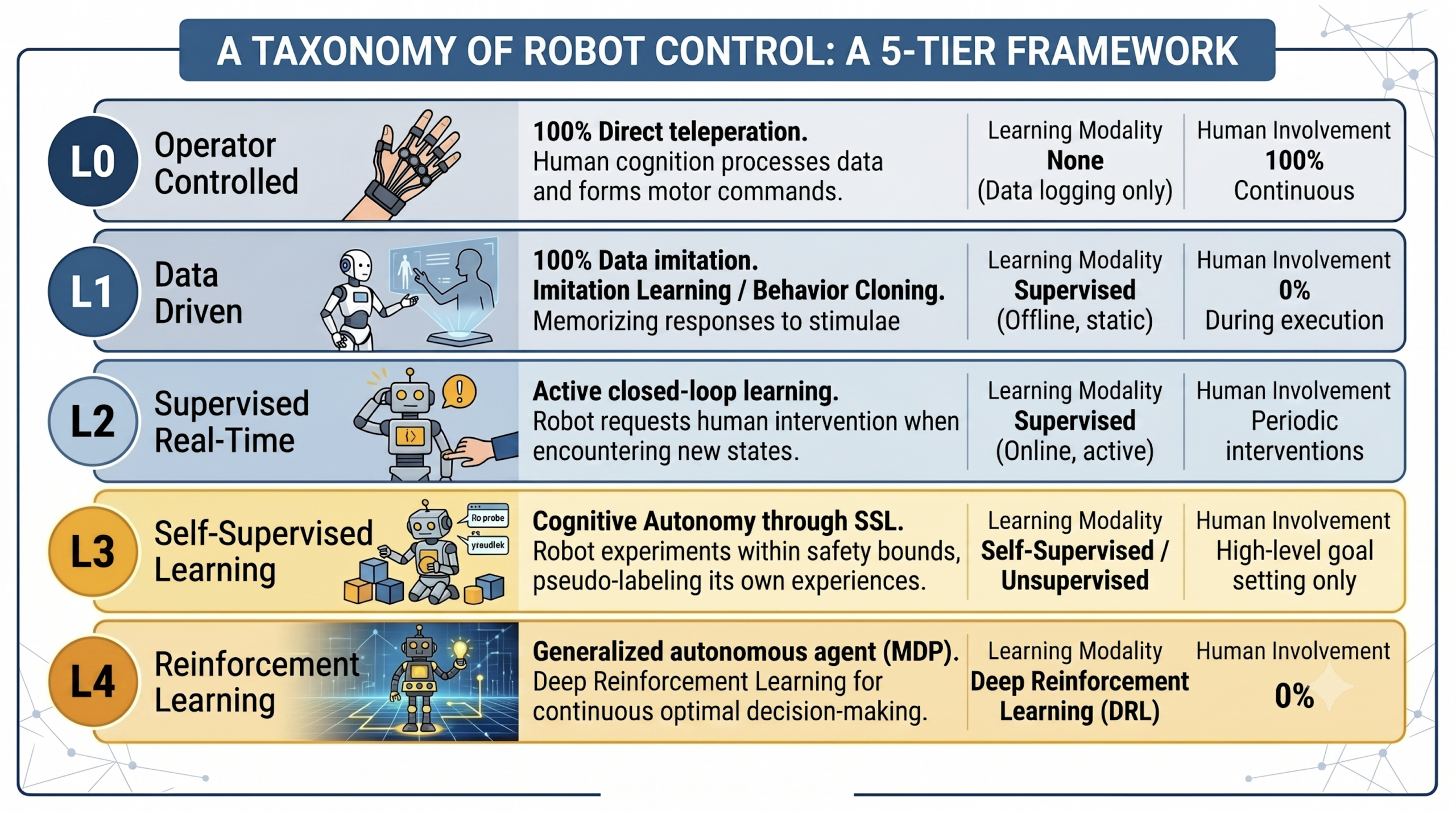
Earlier than we are able to speak about the best way to take a look at autonomous techniques, it helps to be exact about what sort of system we’re really testing.
In a paper revealed in IJRCAR in March 2026, I proposed a five-level taxonomy that classifies robots by their cognitive and management structure, not by how attentive a human operator is — because the SAE driving levels do — however by how the machine itself is processing data and producing conduct.
Ranges 0 and 1: Teleoperation and imitation. At Stage 0, a human is doing all of the considering. The robotic executes intent instantly through teleoperation. At Stage 1, it has discovered to mimic from recorded demonstrations via conduct cloning and may function with no reside operator, however solely throughout the bounds of what it’s seen. The brittleness right here is well-documented: Robots educated on clear, structured demonstrations wrestle when real-world situations drift even barely from coaching knowledge. A distinct flooring texture, an object positioned at an unfamiliar angle. Testing at these ranges is comparatively tractable, and the tooling is mature.
Stage 2: Supervised real-time studying. The robotic can detect its personal uncertainty, pause safely, request correction, and combine that correction into its future conduct utilizing inverse reinforcement studying. Testing turns into a two-part problem: validating the uncertainty detection mechanism itself, and validating the integrity of the educational replace triggered by every corrective intervention.
Stage 3: Self-supervised studying. The robotic generates its personal coaching indicators via trial and error, annotating its personal successes and failures with out human enter. Right here, the take a look at engineer’s job basically adjustments. You’re now not simply testing mounted conduct. You’re validating a system that’s repeatedly rewriting its personal coverage. Testing must assess not simply present efficiency, but in addition the protection of the educational course of itself.
Stage 4: Reinforcement studying. Full autonomy. The robotic frames each process as an optimization downside and solves it via steady interplay with its setting, usually discovering options a human couldn’t show. At this degree, conventional take a look at case enumeration breaks down. The conduct house is just too giant, too dynamic, and too emergent to enumerate exhaustively.
Every degree up this ladder doesn’t simply add functionality. It additionally provides a basically completely different sort of failure mode and calls for a basically completely different strategy to validation.
The place present security frameworks fall brief
The go-to threat evaluation device in automotive and robotics software program improvement is FMEA (failure mode and results evaluation). In a co-authored paper revealed in IRE Journals (2025), we examined the precise limitations of software program design FMEA when utilized to AI-driven techniques, and what a extra strong strategy appears like.
The core situation is the chance precedence quantity, or RPN, which is FMEA’s customary scoring mechanism. It multiplies Severity, Prevalence, and Detection right into a single rating. The issue turns into apparent the second you set numbers to it: a catastrophic failure rated Severity 10, Prevalence 1, Detection 1 scores 10. So does a average failure rated Severity 1, Prevalence 1, Detection 10. Similar quantity. Utterly completely different risk.
In a conventional deterministic software program system, skilled engineers work round this with judgment. In a neural network-driven system the place failure modes are emergent and context-dependent, that judgment is far more durable to use reliably.
The results of getting it mistaken aren’t only a failed take a look at. They’re deployment delays, legal responsibility publicity, and within the worst circumstances, incidents that set again public belief in a whole product class.
The paper proposes integrating a threat precedence matrix alongside HAZOP (hazard and operability examine) evaluation, strategies that consider threat via richer contextual lenses relatively than collapsing the whole lot right into a single quantity. Grounded in ISO 26262 for useful security and ISO 21434 for automotive cybersecurity, this mixed strategy provides engineers a extra nuanced vocabulary for reasoning about AI-specific failure modes.
The regulatory backdrop reinforces why this issues. ISO 25785-1, the primary worldwide security customary for bipedal robots, was revealed in Might 2025 and covers industrial office deployment solely. ISO 13482, addressing personal-care robots, was up to date in 2025 however predates fashionable basis fashions.
The 2025 revision of ISO 10218-1 for industrial robotics made significant progress, however security researchers are already figuring out gaps in AI-driven humanoids and cell manipulation that the replace doesn’t totally shut. These requirements are important foundations. They want practitioner enter to evolve sooner.
A testing philosophy that scales with autonomy
So what does a extra acceptable testing strategy seem like throughout these management ranges? Right here’s how I give it some thought.
For Ranges 0 and 1, standard verification and validation strategies apply fairly effectively. {Hardware}-in-the-loop (HiL) testing, structured take a look at suites, and systematic boundary testing of the coaching knowledge distribution are achievable and efficient. The important thing addition for Stage 1 is deliberate out-of-distribution (OOD) testing, probing the sides of the coaching corpus deliberately relatively than assuming protection.
For Stage 2, the take a look at technique must broaden to cowl the educational loop itself. Two issues want validation individually:
- The uncertainty quantification mechanism — Does the robotic appropriately determine when it doesn’t know one thing?
- The coverage replace mechanism — Does the corrective enter get built-in safely and precisely?
Logging and replay infrastructure turns into important. Each human intervention ought to be recorded, tagged, and reviewed as a possible sign about the place the coverage is weak.
For Stage 3, formal strategies begin turning into genuinely mandatory relatively than elective. When a system is rewriting its personal coverage via self-supervised studying, the protection constraints on that studying course of must be mathematically specified and verified, not simply empirically examined.
In apply, the toughest a part of Stage 3 validation isn’t the tooling; it’s getting alignment on what “protected exploration” really means on your particular platform earlier than testing begins. Approaches like constrained reinforcement studying and protected exploration algorithms are value constructing into the structure from the beginning, not retrofitting later. Sim-to-real validation cycles have to explicitly stress-test self-supervised behaviors in edge case environments earlier than any real-world deployment.
For Stage 4, the testing philosophy has to shift from test-case enumeration to statistical protection and formal security ensures. Monte Carlo simulation at scale, adversarial setting technology, and area randomization (the identical methods utilized in coaching) also needs to be core instruments in validation. Behavioral specification frameworks that outline what the coverage mustn’t ever do, no matter what it discovers, are as essential as efficiency benchmarks.
The federated studying query
One space that deserves explicit consideration because the business scales towards Stage 4 is federated reinforcement studying, the paradigm the place robotic fleets share coverage updates throughout a community, distributing compute and accelerating studying convergence.
The effectivity beneficial properties are actual and vital. However the testing and validation necessities are qualitatively completely different from single-robot techniques.
When coverage updates circulation peer-to-peer throughout a fleet, the integrity of these updates must be verified on the level of aggregation. Analysis on federated studying safety has documented particular failure modes: knowledge poisoning, the place a compromised node submits manipulated updates; backdoor assaults, the place a set off embedded throughout coaching causes focused misbehavior at inference time; and mannequin inversion, the place gradient sharing inadvertently leaks details about native coaching environments. These aren’t theoretical. They’re empirically demonstrated.
Testing a federated system, subsequently, wants to incorporate adversarial robustness analysis of the aggregation mechanism, not simply the person coverage. Byzantine-fault-tolerant aggregation algorithms like Krum and FedProx, anomaly detection on incoming gradient updates, and cryptographic verification of replace provenance are all engineering decisions that ought to be in scope throughout design and testable throughout validation. Differential privateness methods utilized on the level of gradient sharing supply one other layer of safety, limiting what a compromised replace can reveal or corrupt. These aren’t unique analysis instruments. They’re out there, documented, and more and more essential to deal with as customary apply in any federated deployment.
Bringing it collectively
The development from Stage 0 to Stage 4 is genuinely thrilling. The aptitude being demonstrated throughout autonomous autos, humanoid platforms, and industrial techniques is actual and significant. What the business wants now could be a testing philosophy that matures on the identical tempo.
Which means treating security validation as a first-class design constraint, not a remaining checkpoint. It means constructing HAZOP and Danger Precedence Matrix evaluation into the software program improvement course of from the beginning, not pulling out a FMEA spreadsheet earlier than launch. It means defining what constitutes satisfactory protection for a self-supervised or RL-trained system earlier than deploying it, not after the primary incident.
And it means giving requirements our bodies the practitioner suggestions they should evolve ISO 26262, ISO 21434, and the rising bipedal robotic requirements sooner than the know-how is outpacing them.
The robots are getting smarter sooner than the validation frameworks designed to certify them. Closing that hole isn’t a regulatory downside or a analysis downside in isolation. It’s an engineering tradition downside. It will get solved when testing is handled as a first-class design self-discipline from day one, not a remaining gate earlier than launch.
For these engaged on autonomous techniques at any of those ranges: at what level does the complexity of the system make conventional test-case enumeration genuinely out of date, and what have you ever discovered really replaces it? I’d particularly like to listen to from anybody navigating Stage 3 or Stage 4 validation in manufacturing.
 Submit your session concept for the 2026 RoboBusiness
Submit your session concept for the 2026 RoboBusinessIn regards to the writer
 Atharv Kolhar is a workers take a look at automation engineer at Determine AI. There, he works on hardware-in-the-loop take a look at infrastructure for the Figure 03 humanoid robotic and the testing of important robotic software program. With a profession throughout humanoid robotics, autonomous lidar sensing, and electrical autos, he makes a speciality of verification for safety-critical autonomous techniques, beforehand constructing the software program take a look at self-discipline behind Aeva Applied sciences’ ASPICE Stage 2 certification, with earlier roles at Lucid Motors and NIO.
Atharv Kolhar is a workers take a look at automation engineer at Determine AI. There, he works on hardware-in-the-loop take a look at infrastructure for the Figure 03 humanoid robotic and the testing of important robotic software program. With a profession throughout humanoid robotics, autonomous lidar sensing, and electrical autos, he makes a speciality of verification for safety-critical autonomous techniques, beforehand constructing the software program take a look at self-discipline behind Aeva Applied sciences’ ASPICE Stage 2 certification, with earlier roles at Lucid Motors and NIO.
Kolhar is a voting member of IEEE P2817, the working group writing the worldwide customary for autonomous techniques verification, a committee member of ASTM F45.06 on legged robotic techniques, and a peer reviewer for IEEE IROS and IEEE Transactions on Automation Science and Engineering.
The views expressed on this article are solely his personal and don’t signify the place, opinion, or stance of his employer or any affiliated group.
Editor’s notes: This text attracts on two revealed papers: “Standardizing Robot Control Levels: A Framework for Autonomous Operation, Real-Time Navigation, and Federated Reinforcement Learning” (IJRCAR, Vol. 14, Concern 3, March 2026) and “Enhancing Software DFMEA Processes through ISO 26262 and ISO 21434: Addressing RPN Limitations with Risk Priority Matrix and HAZOP Integration” (IRE Journals, Vol. 8, Concern 7, 2025).
The put up We all know the best way to construct smarter robots. Now, we have to study smarter methods to check them appeared first on The Robotic Report.


