
The most recent set of open-source fashions from Google are right here, the Gemma 4 household has arrived. Open-source fashions are getting very fashionable lately attributable to privateness considerations and their flexibility to be simply fine-tuned, and now we now have 4 versatile open-source fashions within the Gemma 4 household and so they appear very promising on paper. So with none additional ado let’s decode and see what the hype is all about.
The Gemma Household
Gemma is a household of light-weight, open-weight giant language fashions developed by Google. It’s constructed utilizing the identical analysis and expertise that powers Google’s Gemini fashions, however designed to be extra accessible and environment friendly.
What this actually means is: Gemma fashions are supposed to run in additional sensible environments, like laptops, client GPUs and even cellular gadgets.
They arrive in each:
- Base variations (for fine-tuning and customization)
- Instruction-tuned (IT) variations (prepared for chat and normal utilization)
So these are the fashions that come underneath the umbrella of the Gemma 4 household:
- Gemma 4 E2B: With ~2B efficient parameters, it’s a multimodal mannequin optimized for edge gadgets like smartphones.
- Gemma 4 E4B: Just like the E2B mannequin however this one comes with ~4B efficient parameters.
- Gemma 4 26B A4B: It’s a 26B parameters combination of consultants mannequin, it prompts solely 3.8B parameters (~4B energetic parameters) throughout inference. Quantized variations of this mannequin can run on client GPUs.
- Gemma 4 31B: It’s a dense mannequin with 31B parameters, it’s essentially the most highly effective mannequin on this lineup and it’s very effectively fitted to fine-tuning functions.
The E2B and E4B fashions function a 128K context window, whereas the bigger 26B and 31B function a 256K context window.
Observe: All of the fashions can be found each as base mannequin and ‘IT’ (instruction-tuned) mannequin.
Beneath are the benchmark scores for the Gemma 4 fashions:
Key Options of Gemma 4
- Code era: The Gemma 4 fashions can be utilized for code era, the LiveCodeBench benchmark scores look good too.
- Agentic techniques: The Gemma 4 fashions can be utilized domestically inside agentic workflows, or self-hosted and built-in into production-grade techniques.
- Multi-Lingual techniques: These fashions are educated on over 140 languages and can be utilized to assist varied languages or translation functions.
- Superior Brokers: These fashions have a big enchancment in math and reasoning in comparison with the predecessors. They can be utilized in brokers requiring multi-step planning and considering.
- Multimodality: These fashions can inherently course of photos, movies and audio. They are often employed for duties like OCR and speech recognition.
Entry Gemma 4 through Hugging Face?
Gemma 4 is launched underneath Apache 2.0 license, you possibly can freely construct with the fashions and deploy the fashions on any setting. These fashions will be accessed utilizing Hugging Face, Ollama and Kaggle. Let’s attempt to check the ‘Gemma 4 26B A4B IT’ by the inference suppliers on Hugging Face, this may give us a greater image of the capabilities of the mannequin.
Pre-Requisite
Hugging Face Token:
- Go to https://huggingface.co/settings/tokens
- Create a brand new token and configure it with the identify and verify the under containers earlier than creating the token.
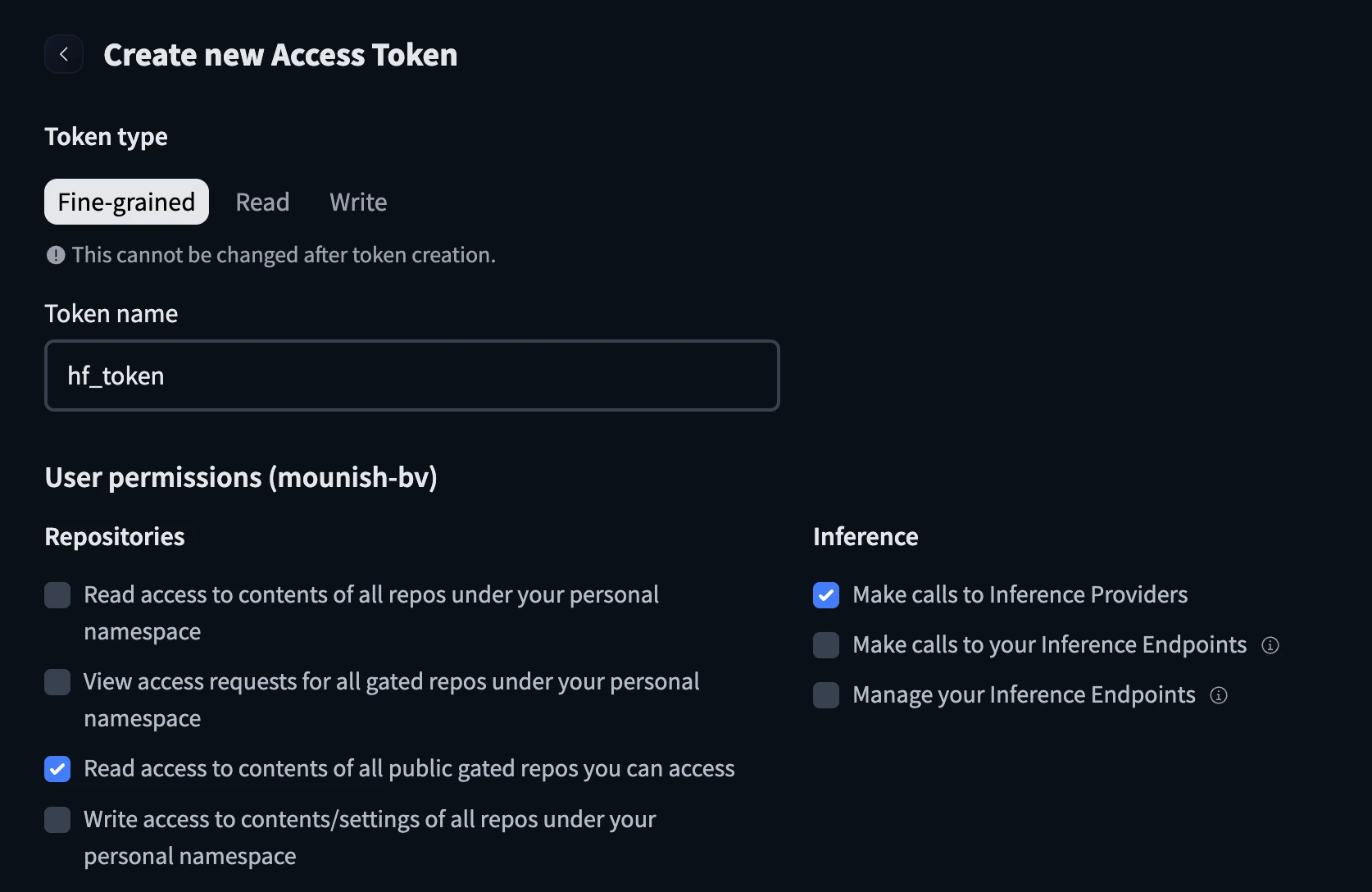
- Hold the cuddling face token helpful.
Python Code
I’ll be utilizing Google Colab for the demo, be happy to make use of what you want.
from getpass import getpass
hf_key = getpass("Enter Your Hugging Face Token: ")Paste the Hugging Face token when prompted:

Let’s attempt to create a frontend for an e-commerce web site and see how the mannequin performs.
immediate="""Generate a contemporary, visually interesting frontend for an e-commerce web site utilizing solely HTML and inline CSS (no exterior CSS or JavaScript).
The web page ought to embrace a responsive structure, navigation bar, hero banner, product grid, class part, product playing cards with photos/costs/buttons, and a footer.
Use a clear fashionable design, good spacing, and laptop-friendly structure.
"""Sending request to the inference supplier:
import os
from huggingface_hub import InferenceClient
consumer = InferenceClient(
api_key=hf_key,
)
completion = consumer.chat.completions.create(
mannequin="google/gemma-4-26B-A4B-it:novita",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
],
}
],
)
print(completion.selections[0].message)
After copying the code and creating the HTML, that is the consequence I acquired:
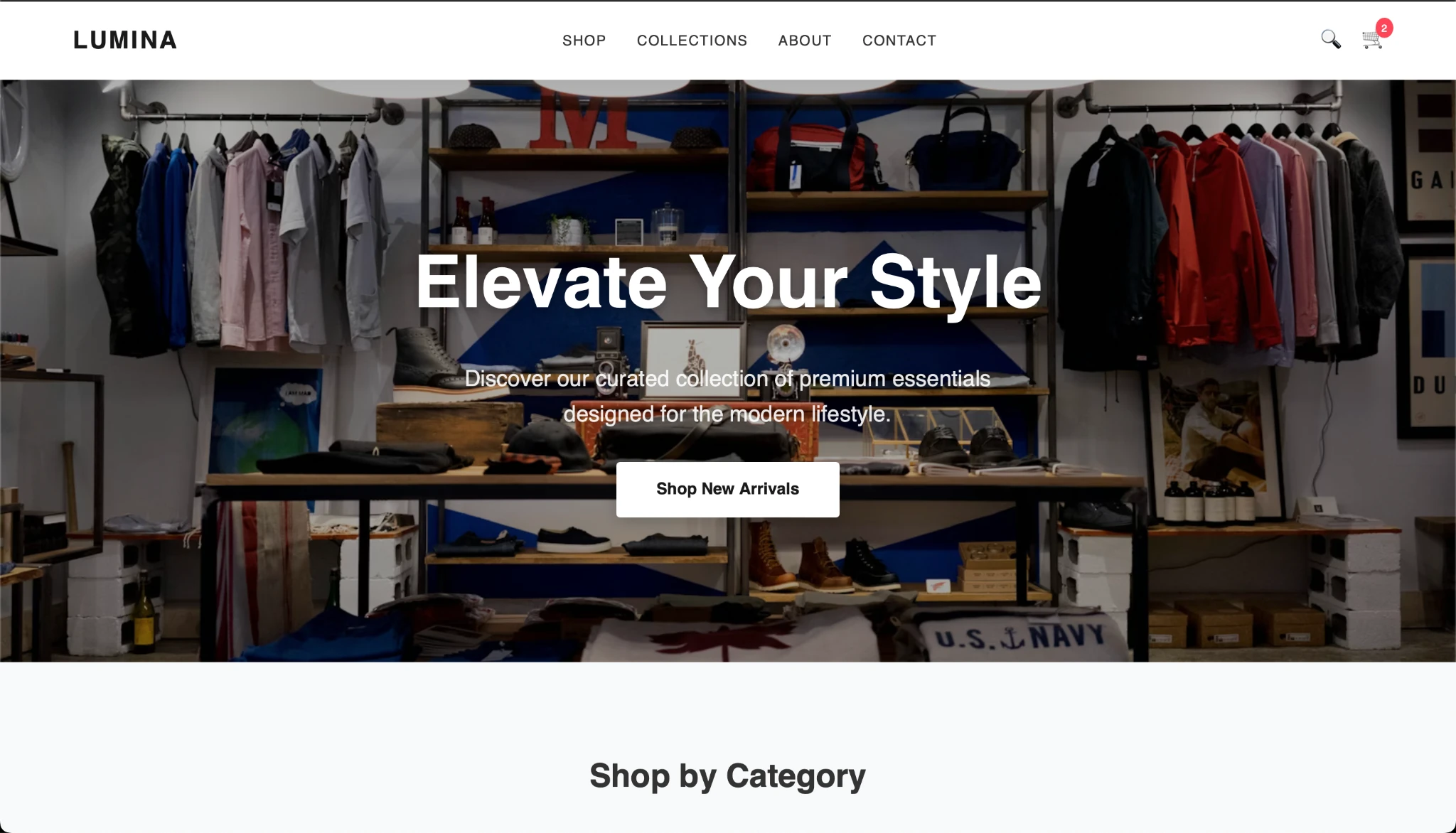
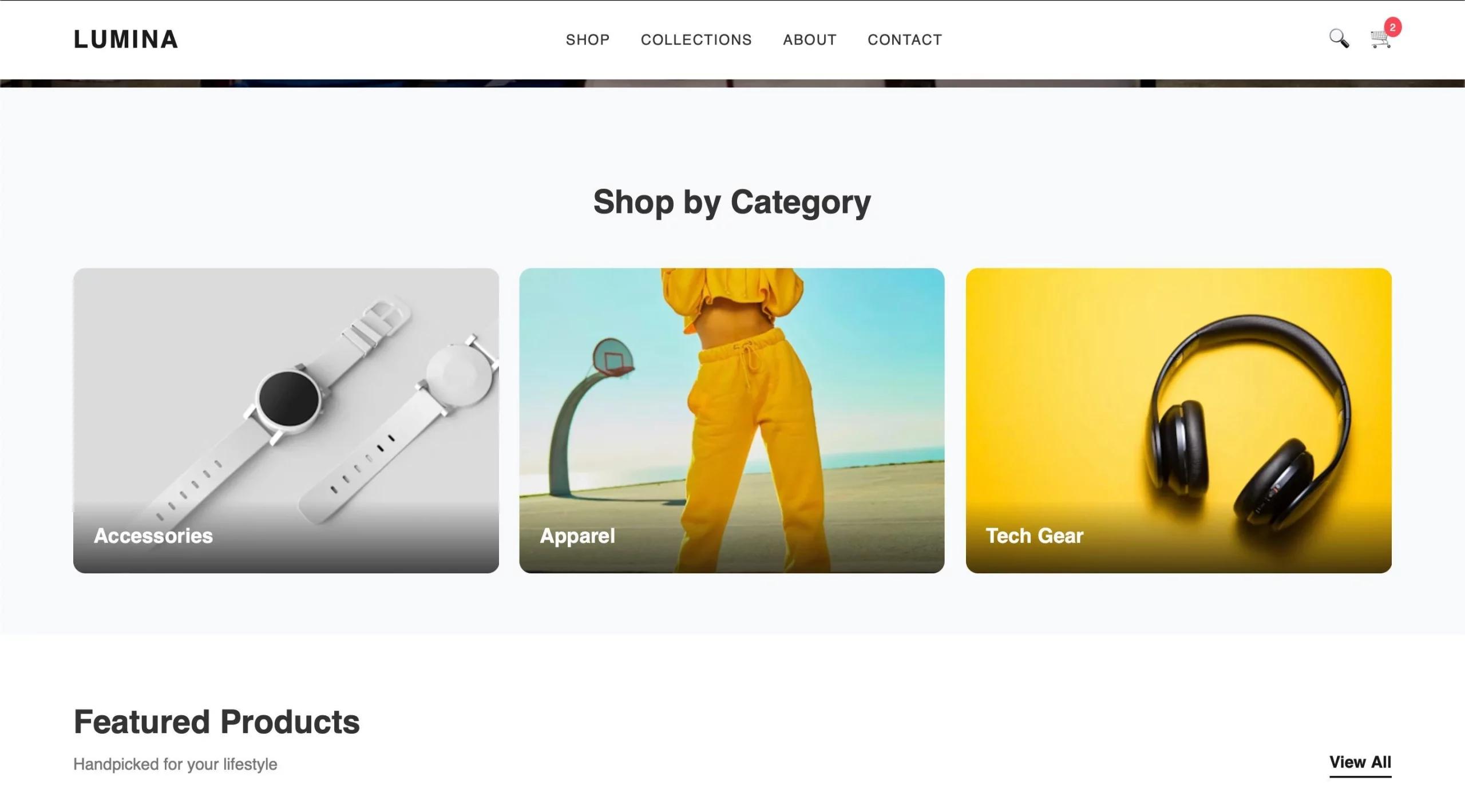
The output appears good and the Gemma mannequin appears to be performing effectively. What do you assume?
Conclusion
The Gemma 4 household not solely appears promising on paper however in outcomes too. With versatile capabilities and the totally different fashions constructed for various wants, the Gemma 4 fashions have gotten so many issues proper. Additionally with open-source AI getting more and more common, we should always have choices to strive, check and discover the fashions that higher go well with our wants. Additionally it’ll be attention-grabbing to see how gadgets like mobiles, Raspberry Pi, and many others profit from the evolving memory-efficient fashions sooner or later.
Continuously Requested Questions
A. E2B means 2.3B efficient parameters. Whereas complete parameters together with embeddings attain about 5.1B.
A. Massive embedding tables are used primarily for lookup operations, in order that they enhance complete parameters however not the mannequin’s efficient compute dimension.
A. Combination of Specialists prompts solely a small subset of specialised professional networks per token, bettering effectivity whereas sustaining excessive mannequin capability. The Gemma 4 26B is a MoE mannequin.
![]()
Enthusiastic about expertise and innovation, a graduate of Vellore Institute of Expertise. At present working as a Information Science Trainee, specializing in Information Science. Deeply eager about Deep Studying and Generative AI, wanting to discover cutting-edge strategies to unravel advanced issues and create impactful options.
Login to proceed studying and revel in expert-curated content material.


