
Liquid Basis Fashions (LFM 2) outline a brand new class of small language fashions designed to ship robust reasoning and instruction-following capabilities straight on edge gadgets. In contrast to massive cloud-centric LLMs, LFM 2 focuses on effectivity, low latency, and reminiscence consciousness whereas nonetheless sustaining aggressive efficiency. This design makes it a compelling alternative for functions on cellular gadgets, laptops, and embedded techniques the place compute and energy stay constrained, however reliability is vital.
The core LFM 2 dense fashions are available sizes of 350M, 700M, 1.2B, and a couple of.6B parameters, every supporting a 32,768-token context window. This unusually lengthy context for fashions of this measurement allows richer reasoning, longer conversations, and higher document-level understanding with out sacrificing deployability. When paired with DPO, groups can effectively align LFM 2 to particular behaviors reminiscent of tone, security constraints, area focus, or instruction-following fashion. Groups obtain this utilizing easy desire information as an alternative of pricey reinforcement studying pipelines. As a result of DPO straight fine-tunes the bottom mannequin with out requiring a separate reward mannequin, it retains coaching and inference light-weight, making it particularly well-suited for edge-focused SLMs the place compute, reminiscence, and stability are vital. This mixture permits LFM 2 to stay quick and compact whereas nonetheless reflecting person or product-specific preferences.
On this article, we shall be masking how we will fine-tune the LFM2-700M mannequin with DPO. So, with none additional ado, let’s dive proper in.
Understanding LFM 2: Structure and Efficiency
Liquid Basis Fashions (LFM 2) symbolize a brand new technology of hybrid small language fashions optimized from the bottom up for edge and on-device use. The structure departs from commonplace transformer-only designs by combining multiplicative gated short-range convolutional layers with a restricted variety of grouped question consideration (GQA) blocks. Researchers recognized this hybrid setup utilizing hardware-in-the-loop structure search below tight latency and reminiscence constraints, enabling environment friendly utilization of CPUs and different embedded accelerators. By counting on quick convolutions for native context and sparse consideration for international reasoning, LFM 2 reduces KV-cache necessities and inference price in comparison with dense attention-heavy fashions.
Extra importantly, LFM 2 achieves important pace and reminiscence advantages with out sacrificing high quality. Benchmarks present that LFM 2 fashions provide as much as 2x sooner prefill and decode speeds on CPU relative to comparable fashions, and your complete coaching pipeline might be 3x extra environment friendly than their predecessors. This efficiency benefit makes them well-suited for real-time functions the place low latency is vital, reminiscent of cellular assistants, embedded robotics, real-time translation, and on-device summarization, particularly when cloud connectivity is unreliable or undesirable.
Throughout commonplace language benchmarks, LFM 2 fashions outperform many equally sized small fashions in areas reminiscent of instruction following, reasoning, multilingual understanding, and arithmetic. For instance, the flagship 2.6B variant achieves robust outcomes on benchmarks like GSM8K for mathematical reasoning and IFEval for instruction adherence, rivaling fashions with considerably bigger parameter counts. Along with dense language duties, the LFM 2 household has been prolonged into multimodal areas reminiscent of vision-language (LFM 2-VL) and audio (LFM 2-Audio) whereas retaining the core effectivity ideas, making the platform versatile for a variety of AI functions on edge gadgets.
What’s Direct Desire Optimization (DPO)?
Direct Desire Optimization (DPO) is a contemporary fine-tuning approach designed to align language fashions with human preferences in an easier and extra steady means than conventional Reinforcement Studying from Human Suggestions (RLHF). As a substitute of coaching a separate reward mannequin and working complicated reinforcement studying loops (like PPO), DPO straight updates the language mannequin utilizing desire information.
In DPO, the mannequin is skilled on pairs of responses for a similar immediate: one chosen (most popular) and one rejected. These preferences can come from human annotations and even from stronger fashions performing as judges. A reference mannequin (often the unique base mannequin) is used to stabilize coaching, and the target encourages the fine-tuned mannequin to assign larger likelihood to most popular responses and decrease likelihood to rejected ones. This makes DPO simpler to implement, extra predictable, and considerably extra resource-efficient.
Execs of Direct Desire Optimization
- Easy to implement: No want to coach or preserve a separate reward mannequin.
- Secure and predictable: Avoids most of the instabilities related to PPO-based RLHF.
- Compute-efficient: Straight fine-tunes the mannequin with out costly reinforcement studying loops.
- Effectively-suited for SLMs: Particularly efficient when working with smaller fashions like LFM 2.
Cons of Direct Desire Optimization
- Restricted suggestions expressiveness: Works primarily with binary (most popular vs. rejected) suggestions.
- Much less versatile reward design: Can’t encode complicated, multi-objective reward capabilities as simply as full RLHF.
Finetuning LFM 2-700M
So the mannequin we selected to finetune is LFM2-700M. Since it is a small mannequin, will probably be efficient and shall be faster to fine-tune. Be at liberty to fine-tune different fashions of the LFM2 household if you want.
The dataset we shall be utilizing can be mlabonne/orpo-dpo-mix-40k. The mlabonne/orpo-dpo-mix-40k dataset is a preference-based coaching corpus particularly designed for DPO (Direct Desire Optimization) or ORPO (Off-Coverage Reinforcement Desire Optimization) fine-tuning of language fashions. It’s a combination dataset that brings collectively a number of high-quality desire datasets right into a single unified assortment of labeled desire pairs.
The dataset aggregates samples from a number of current desire datasets, every curated for high quality and desire data:
- argilla/Capybara-Preferences – high-quality most popular responses (≥5 ranking)
- argilla/distilabel-intel-orca-dpo-pairs – desire pairs not in GSM8K with high-scored chosen responses
- argilla/ultrafeedback-binarized-preferences-cleaned – massive cleaned desire set
- argilla/distilabel-math-preference-dpo – math-related desire pairs
- M4-ai/prm_dpo_pairs_cleaned – cleaned desire pairs
- jondurbin/truthy-dpo-v0.1 – extra desire sources
- unalignment/toxic-dpo-v0.2 – a smaller set that features difficult/poisonous prompts (usually filtered out in apply)
So, let’s proceed with the fine-tuning half now. We use LFM2-700M as our base mannequin since it’s a small, environment friendly language mannequin that fine-tunes rapidly and suits comfortably on a T4 GPU.
Step 1: Setting Up the Coaching Atmosphere
On this step, we set up the required libraries for mannequin loading, desire optimization, and parameter-efficient fine-tuning. Utilizing mounted or minimal variations ensures compatibility between Transformers, TRL, and PEFT, particularly when working on Google Colab.
!pip set up transformers==4.54.0 trl>=0.18.2 peft>=0.15.2 -qStep 2: Importing Core Libraries and Verifying Variations
Right here we import PyTorch, Transformers, and TRL, which kind the core of our coaching pipeline. Printing the model numbers helps guarantee reproducibility and avoids refined points attributable to incompatible library variations.
import torch
import transformers
import trl
import os
print(f"📦 PyTorch model: {torch.__version__}")
print(f"🤗 Transformers model: {transformers.__version__}")
print(f"📊 TRL model: {trl.__version__}")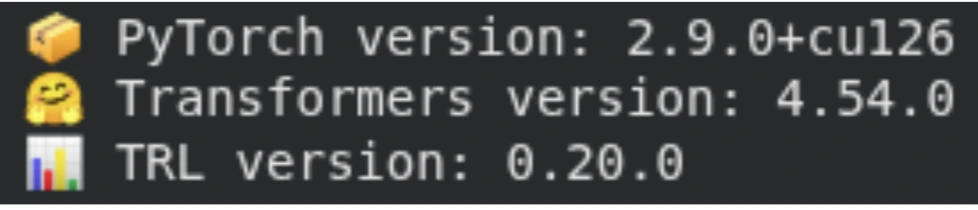
Step 3: Downloading the Tokenizer and Base Mannequin
We load the LFM2-700M tokenizer and mannequin straight from Hugging Face. The tokenizer converts uncooked textual content into token IDs, whereas the mannequin is loaded with computerized system placement utilizing device_map=”auto”, permitting it to effectively make the most of the accessible GPU. At this stage, we confirm the mannequin measurement, parameter depend, and vocabulary measurement.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "LiquidAI/LFM2-700M" # <- alter mannequin right here to make use of LiquidAI/LFM2-350M or LFM2-1.2B
print("📚 Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
print("🧠 Loading mannequin...")
mannequin = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto",
)
print("✅ Native mannequin loaded efficiently!")
print(f"🔢 Parameters: {mannequin.num_parameters():,}")
print(f"📖 Vocab measurement: {len(tokenizer)}")
print(f"💾 Mannequin measurement: ~{mannequin.num_parameters() * 2 / 1e9:.1f} GB (bfloat16)")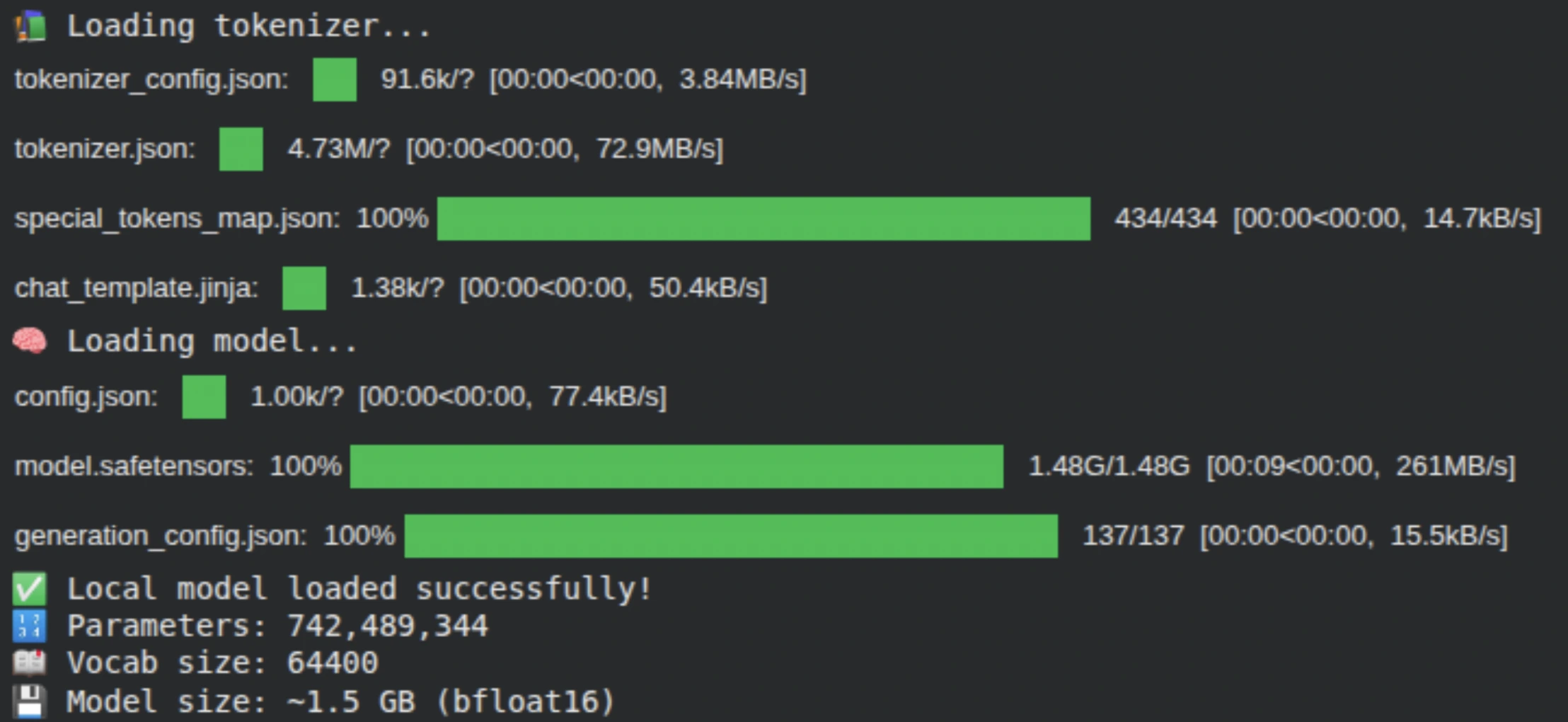
Step 4: Loading and Getting ready the Desire Dataset
We load the mlabonne/orpo-dpo-mix-40k dataset, which incorporates desire pairs consisting of a immediate, a most popular response, and a rejected response. To maintain coaching environment friendly, we use a subset of the info and cut up it into coaching and analysis units, enabling us to trace alignment efficiency throughout coaching.
from datasets import load_dataset
print("📥 Loading DPO dataset...")
dataset_dpo = load_dataset("mlabonne/orpo-dpo-mix-40k", cut up="prepare[:2500]") # variety of samples are straight proportional to the coaching time.
dataset_dpo = dataset_dpo.train_test_split(test_size=0.1, seed=42)
train_dataset_dpo, eval_dataset_dpo = dataset_dpo['train'], dataset_dpo['test']
print("✅ DPO Dataset loaded:")
print(f" 📚 Prepare samples: {len(train_dataset_dpo)}")
print(f" 🧪 Eval samples: {len(eval_dataset_dpo)}")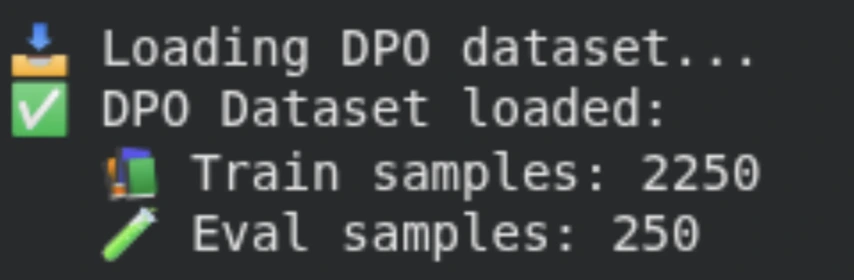
Step 5: Enabling Parameter-Environment friendly High-quality-Tuning with LoRA
As a substitute of fine-tuning all mannequin parameters, we apply LoRA (Low-Rank Adaptation) utilizing PEFT. We goal key elements of the LFM2 structure, together with feed-forward (GLU), consideration, and convolutional layers. This drastically reduces the variety of trainable parameters, making fine-tuning sooner and extra memory-efficient.
from peft import LoraConfig, get_peft_model, TaskType
GLU_MODULES = ["w1", "w2", "w3"]
MHA_MODULES = ["q_proj", "k_proj", "v_proj", "out_proj"]
CONV_MODULES = ["in_proj", "out_proj"]
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8, # <- decrease values = fewer parameters
lora_alpha=16,
lora_dropout=0.1,
target_modules=GLU_MODULES + MHA_MODULES + CONV_MODULES,
bias="none", # if we outline bias then we'll extra params to coach
modules_to_save=None,
)
lora_model = get_peft_model(mannequin, lora_config)
lora_model.print_trainable_parameters()
print("✅ LoRA configuration utilized!")
print(f"🎛️ LoRA rank: {lora_config.r}")
print(f"📊 LoRA alpha: {lora_config.lora_alpha}")
print(f"🎯 Goal modules: {lora_config.target_modules}")
Step 6: Defining the DPO Coaching Configuration
Right here, we specify the Direct Desire Optimization (DPO) coaching settings, reminiscent of studying charge, batch measurement, gradient accumulation, and analysis technique. These parameters gently align the mannequin’s habits utilizing desire information whereas sustaining stability on restricted GPU {hardware}.
To minimize your coaching time, you should utilize max_steps as an alternative of num_train_epochs, too.
from trl import DPOConfig, DPOTrainer
# DPO Coaching configuration
dpo_config = DPOConfig(
output_dir="./lfm2-dpo",
num_train_epochs=1,
per_device_train_batch_size=1,
learning_rate=1e-6,
lr_scheduler_type="linear", # also can use cosine
gradient_accumulation_steps=4,
logging_steps=10,
save_strategy="epoch",
eval_strategy="epoch",
bf16=False # <- not all colab GPUs assist bf16
)
# Create DPO coach
print("🏗️ Creating DPO coach...")
dpo_trainer = DPOTrainer(
mannequin=lora_model,
args=dpo_config,
train_dataset=train_dataset_dpo,
eval_dataset=eval_dataset_dpo,
processing_class=tokenizer,
)
Step 7: Initializing the DPO Coach
The DPO Coach brings collectively the LoRA-wrapped mannequin, tokenizer, datasets, and coaching configuration. It handles the comparability between chosen and rejected responses and computes the DPO loss that guides the mannequin towards most popular outputs.
# Begin DPO coaching
print("n🚀 Beginning DPO coaching...")
dpo_trainer.prepare()
print("🎉 DPO coaching accomplished!")
# Save the DPO mannequin
dpo_trainer.save_model()
print(f"💾 DPO mannequin saved to: {dpo_config.output_dir}")
Usually, we’ll see all our metrics at each tenth step right here when the mannequin is being skilled.
Step 8: Coaching the Mannequin with DPO
We now start DPO coaching. Throughout this part, the mannequin learns to assign larger likelihoods to most popular responses and decrease likelihoods to rejected ones. Coaching metrics are logged at common intervals, permitting us to observe alignment progress.
print("n🔄 Merging LoRA weights...")
merged_model = lora_model.merge_and_unload()
merged_model.save_pretrained("./lfm2-lora-merged")
tokenizer.save_pretrained("./lfm2-lora-merged")
print("💾 Merged mannequin saved to: ./lfm2-lora-merged")Step 9: Merging LoRA Weights and Saving the Remaining Mannequin
After coaching, we merge the LoRA adapters again into the bottom mannequin to create a standalone fine-tuned checkpoint. The merged mannequin and tokenizer are saved regionally, making them prepared for inference or deployment.
Optionally, we will push the fine-tuned mannequin to the Hugging Face Hub, permitting it to be simply shared, versioned, and reused throughout tasks or deployment environments.
merged_model.push_to_hub("/LFM2-700M-DPO-FT")
tokenizer.push_to_hub("/LFM2-700M-DPO-FT") 
Lastly, you’d be capable of test your mannequin pushed into your Hugging Face account, prepared for use by the general public.
Step 10: Operating Inference with the High-quality-Tuned LFM 2 Mannequin
Now that the mannequin has been fine-tuned and pushed to the Hugging Face Hub, the ultimate step is to load the mannequin and generate responses. This step validates that the Direct Desire Optimization (DPO) coaching has efficiently aligned the mannequin’s habits and that it may possibly produce high-quality outputs throughout inference.
We load the fine-tuned checkpoint utilizing AutoModelForCausalLM and AutoTokenizer, guaranteeing the mannequin runs effectively by leveraging computerized system placement and reduced-precision weights. We then cross a easy immediate via the tokenizer utilizing the chat template and generate textual content with managed sampling parameters, reminiscent of temperature and repetition penalty, to encourage coherent and preference-aligned responses.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load mannequin and tokenizer
model_id = "skhamzah123/LFM2-700M-DPO-FT"
mannequin = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="bfloat16",
# attn_implementation="flash_attention_2" <- uncomment on suitable GPU
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Generate reply
immediate = "What's LLMs in easy phrases?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(mannequin.system)
output = mannequin.generate(
input_ids,
do_sample=True,
temperature=0.3,
min_p=0.15,
repetition_penalty=1.05,
max_new_tokens=512,
)
print(tokenizer.decode(output[0], skip_special_tokens=False))
As seen from the output, the mannequin responds in a transparent and well-structured method, demonstrating that the DPO fine-tuning has successfully improved instruction following whereas sustaining the effectivity and deployability anticipated from an edge-friendly Small Language Mannequin.
Conclusion
On this weblog, we explored how Direct Desire Optimization (DPO) effectively aligns Liquid Basis Fashions (LFM 2) with desired behaviors and preferences. By fine-tuning LFM2-700M, we confirmed that efficient alignment doesn’t require complicated reinforcement studying pipelines or large-scale computation. As a substitute, DPO presents an easier, extra steady, and resource-efficient various, making it notably well-suited for small language fashions and edge deployments.
Utilizing LoRA-based parameter-efficient fine-tuning, we tailored the mannequin whereas coaching solely a small subset of parameters, protecting reminiscence utilization and coaching prices low. This workflow permits practitioners to align fashions on modest {hardware} whereas preserving the effectivity and efficiency traits of LFM 2. After coaching, the result’s a standalone checkpoint that’s prepared for inference, deployment, or sharing.
You guys also can experiment with different LFM 2 variants, together with smaller or bigger mannequin sizes, and check out totally different desire datasets tailor-made to particular domains or use instances. This flexibility makes the strategy broadly relevant, whether or not the aim is instruction tuning, reasoning enhancement, or domain-specific alignment, offering a sensible and extensible basis for constructing aligned, deployable language fashions.
![]()
Knowledge Scientist @ Analytics Vidhya | CSE AI and ML @ VIT Chennai
Obsessed with AI and machine studying, I am wanting to dive into roles as an AI/ML Engineer or Knowledge Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to convey progressive options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into information engineering, guaranteeing I keep forward and ship impactful tasks.
Login to proceed studying and revel in expert-curated content material.

