![What is Seedance 2.0? [Features, Architecture, and More]](https://cdn.analyticsvidhya.com/wp-content/uploads/2026/02/Seedance-2.0-.png "What is Seedance 2.0? [Features, Architecture, and More]")
Just a few years in the past, producing a picture from textual content felt magical. Then text-to-video turned prompts into transferring scenes. Now fashions generate full video sequences with out cameras, actors, or enhancing timelines. ByteDance’s Seedance 2.0 pushes this additional. As an alternative of quick silent clips, it delivers a multimodal system that plans scenes in pictures, synchronizes audio natively, and helps reference-driven management throughout textual content, picture, video, and sound. This text breaks down its structure, key options, and the way it compares to Sora 2, Veo 3.1, and Kling 3.0.
What’s Seedance 2.0?
Seedance 2.0 is ByteDance’s superior multimodal video technology mannequin that creates cinematic, multi-shot movies with synchronized audio. It accepts textual content, picture, video, and audio inputs, enabling reference-driven management and structured scene planning inside a unified diffusion-based structure.
Supply: Ivanna | AI Art & Prompts
Entry Seedance 2.0?
Proper now, Seedance 2.0 doesn’t have a totally open world API, however some third-party apps and mannequin internet hosting platforms present restricted entry. Most of those are UI-based inventive instruments the place you’ll be able to generate movies with utilization caps, area restrictions, or invite-only entry.
You can check out this page for reference.
Key Options
Immersive Audio-Visible Expertise
An immersive audio-visual expertise is delivered by distinctive movement stability and native audio-video joint technology. By producing synchronized visuals and sound inside the identical technology course of, the mannequin achieves ultra-realistic output that feels cohesive and cinematic moderately than artificially assembled.
Create with Director-level Management
Help for photos, audio, and video as reference inputs permits creators to rework concepts into visuals with a excessive diploma of management. Efficiency, lighting, shadow, and digicam motion can all be guided, permitting for structured scene creation that resembles intentional path moderately than prompt-only technology.
Cinematic, Business-Aligned Output
Notice: All of the above movies are taken from ByteDance’s website.
Efficiency of Seedance 2.0
Benchmark outcomes from SeedVideoBench-2.0 point out main efficiency throughout a number of process classes. The mannequin performs strongly in text-to-video, image-to-video, and multimodal duties, demonstrating constant functionality throughout totally different technology situations.
How Does Seedance 2.0 Work?
Seedance 2.0 operates as a unified multimodal diffusion system that collectively generates video and audio from structured conditioning inputs. As an alternative of treating textual content, photos, video references, and sound as separate indicators, it encodes them right into a shared latent house and performs coordinated denoising throughout time. The result’s a multi-shot, synchronized audio-video sequence generated inside a single pipeline.
Right here is how the system is structured.
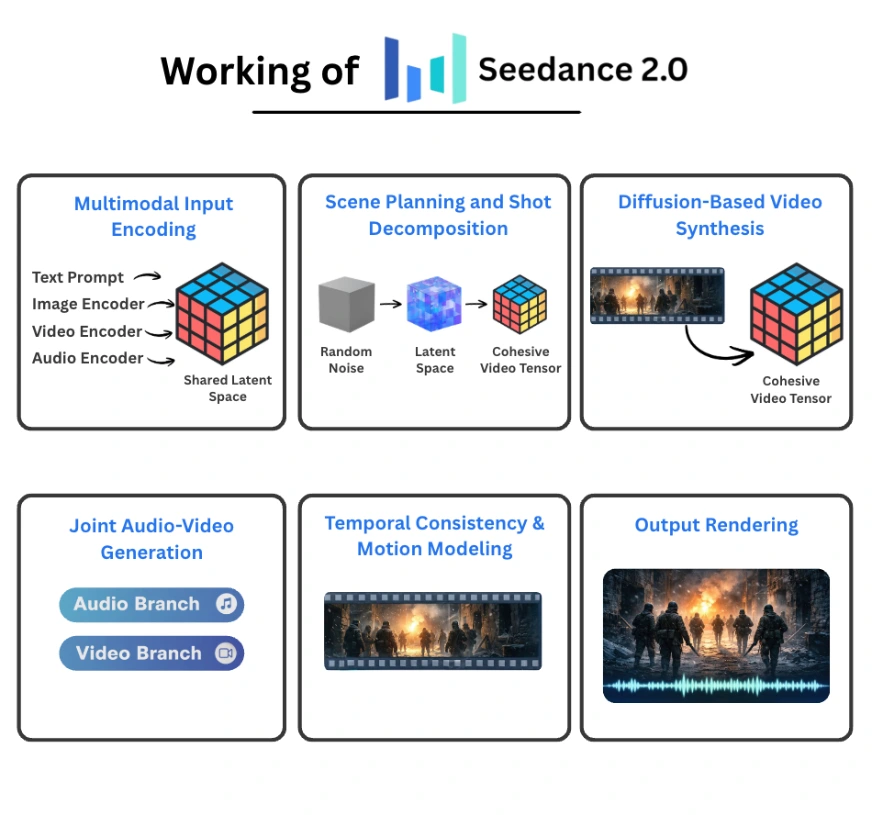
Multimodal Enter Encoding
Every modality is processed by a devoted encoder:
- A textual content encoder converts prompts into semantic embeddings.
- A picture encoder transforms photos into patch-level visible tokens.
- A video encoder produces spatiotemporal tokens that seize movement and scene construction.
- An audio encoder extracts waveform or spectrogram representations.
All embeddings are projected right into a shared latent illustration. This unified house permits cross-modal interplay. A textual instruction about lighting can affect visible tone, whereas a music reference can form pacing and motion. As a result of all the pieces lives in the identical representational house, conditioning is coherent moderately than loosely stitched collectively.
Scene Planning and Shot Decomposition
Earlier than body synthesis begins, Seedance interprets the immediate and constructs a structured inside plan.
As an alternative of producing a single uninterrupted clip, the system:
- Parses narrative intent.
- Breaks the scene into a number of pictures.
- Plans transitions and continuity throughout them.
This planning layer features like an automatic storyboard generator. Character identification, lighting circumstances, and spatial structure are preserved throughout cuts. That stops identification drift and abrupt visible inconsistencies that usually happen in naive video diffusion methods.
The end result isn’t just movement over time, however a sequence that resembles intentional cinematography.
Diffusion-Primarily based Video Synthesis
Video technology is dealt with by a spatiotemporal diffusion course of.
The pipeline works as follows:
- Initialize random noise in latent house.
- Situation the denoising steps on multimodal embeddings.
- Iteratively refine spatial and temporal representations.
- Produce a coherent video tensor.
In contrast to picture diffusion, video diffusion should preserve consistency throughout time. The transformer spine attends throughout frames to protect object construction and movement continuity. This reduces flicker, prevents object morphing, and stabilizes digicam motion.
Joint Audio-Video Era
Some of the distinctive components of Seedance 2.0 is simultaneous audio and video technology.
The structure consists of:
- A video department answerable for visible denoising.
- An audio department answerable for waveform technology.
These branches trade temporal indicators throughout inference. When a visual occasion happens within the video stream, the audio department generates corresponding sound aligned to that actual second. Lip motion can synchronize with speech. Environmental results match bodily interactions.
Producing each modalities collectively improves alignment in comparison with methods that connect audio after video synthesis is full.
Temporal Stability and Movement Modeling
Video synthesis introduces challenges that static picture fashions don’t face:
- Lengthy-range temporal coherence
- Constant character identification
- Bodily believable movement
Seedance addresses these by:
- Spatiotemporal consideration mechanisms
- Movement-aware latent conditioning
- Giant-scale video-audio coaching information
By modeling movement trajectories as an alternative of unbiased frames, the system maintains smoother transitions and extra secure object habits throughout time.
Output Rendering
In spite of everything deliberate pictures are generated:
- Shot segments are mixed internally.
- Audio streams are aligned with the visible timeline.
- The ultimate video file is rendered.
The output can span as much as roughly 15 seconds and will embrace a number of digicam angles inside a single technology request.
Seedance 2.0 vs Sora 2
Sora 2 is commonly described as a actuality simulator. It excels in modeling physics, together with gravity, fluid movement, and object permanence even when objects transfer off-screen. For long-duration realism and bodily coherent environments, Sora stays extraordinarily sturdy.
Seedance competes intently on realism however differentiates itself by its quad-modal reference system. In contrast to Sora, which primarily depends on textual content and restricted picture enter, Seedance permits direct task of textual content, photograph, video, and audio references. This allows type switch, movement cloning, and voice-guided technology in methods which might be extra dynamic than Sora’s prompt-based strategy.
One other essential distinction lies in audio technology. Seedance makes use of a dual-branch transformer to generate video and audio concurrently. This results in tighter synchronization between seen occasions and sound. Sora treats audio extra as a secondary course of moderately than a tightly coupled technology stream.
Seedance 2.0 vs Google Veo 3.1
Veo 3.1 gives exact management by masked enhancing and camera-specific instructions resembling pan, tilt, and zoom. This makes it really feel like a digital enhancing suite the place creators can refine particular areas of a body with out regenerating the complete scene.
Seedance takes a reference-driven strategy as an alternative of mask-driven enhancing. As an alternative of manually modifying elements of a video, customers can add reference clips to switch movement type, lighting, or vibe into a brand new technology. If Veo emphasizes surgical enhancing, Seedance emphasizes managed type replication.
When it comes to audio-video alignment, Seedance maintains a bonus because of its joint technology structure. Veo’s synchronization is robust, however not as tightly built-in as Seedance’s simultaneous audio-video diffusion.
Seedance 2.0 vs Kling 3.0
Each Seedance and Kling carry out properly in sustaining character consistency, however their strategies differ.
Kling’s Omni Mode permits customers to bind particular faces, outfits, and components into reusable belongings. That is helpful when constructing recurring characters for episodic content material. It creates a managed asset library that may be reused throughout scenes.
Seedance focuses extra on reference cloning and magnificence switch. As an alternative of binding inside belongings, it permits customers to switch movement, lighting, and efficiency type from exterior media. Kling is stronger for constructing a reusable solid, whereas Seedance is stronger for replicating a selected cinematic really feel from an current reference.
Kling additionally presents sturdy management over dialogue tone and multilingual speech technology. Its synchronization outperforms a number of rivals. Nonetheless, Seedance nonetheless holds a slight edge in frame-accurate audio-video alignment.
Additionally Learn: Prime 10 AI Video Mills
Conclusion
Seedance 2.0 looks like a real step ahead in AI video technology. The quad-modal inputs, tight audio-video sync, and built-in shot planning make it extra than simply one other prompt-to-video instrument. It begins to seem like a light-weight digital manufacturing system. Sora 2, Veo 3.1, and Kling 3 every have clear strengths, however Seedance 2.0 stands out for a way a lot management it offers creators. If world entry opens up and API help expands, this might change into a strong instrument for real-world inventive workflows.
![]()
Hi there, I’m Nitika, a tech-savvy Content material Creator and Marketer. Creativity and studying new issues come naturally to me. I’ve experience in creating result-driven content material methods. I’m properly versed in search engine marketing Administration, Key phrase Operations, Internet Content material Writing, Communication, Content material Technique, Modifying, and Writing.
Login to proceed studying and revel in expert-curated content material.


