
Within the age of more and more giant language fashions and complicated neural networks, optimizing mannequin effectivity has develop into paramount. Weight quantization stands out as an important method for lowering mannequin measurement and enhancing inference pace with out vital efficiency degradation. This information offers a hands-on strategy to implementing and understanding weight quantization, utilizing GPT-2 as our sensible instance.
Studying Targets
- Perceive the basics of weight quantization and its significance in mannequin optimization.
- Be taught the variations between absmax and zero-point quantization strategies.
- Implement weight quantization strategies on GPT-2 utilizing PyTorch.
- Analyze the influence of quantization on reminiscence effectivity, inference pace, and accuracy.
- Visualize quantized weight distributions utilizing histograms for insights.
- Consider mannequin efficiency post-quantization by textual content era and perplexity metrics.
- Discover the benefits of quantization for deploying fashions on resource-constrained units.
This text was printed as part of the Information Science Blogathon.
Understanding Weight Quantization Fundamentals
Weight quantization converts high-precision floating-point weights (usually 32-bit) to lower-precision representations (generally 8-bit integers). This course of considerably reduces mannequin measurement and reminiscence utilization whereas making an attempt to protect mannequin efficiency. The important thing problem lies in sustaining mannequin accuracy whereas lowering numerical precision.
Why Quantize?
- Reminiscence Effectivity: Lowering precision from 32-bit to 8-bit can theoretically scale back mannequin measurement by 75%
- Quicker Inference: Integer operations are usually quicker than floating-point operations
- Decrease Energy Consumption: Decreased reminiscence bandwidth and less complicated computations result in power financial savings
- Deployment Flexibility: Smaller fashions may be deployed on resource-constrained units
Sensible Implementation
Let’s dive into implementing two well-liked quantization strategies: absmax quantization and zero-point quantization.
Setting Up the Setting
First, we’ll arrange our improvement atmosphere with essential dependencies:
import seaborn as sns
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
from copy import deepcopy
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as snsBeneath we’ll look into implementing quantization strategies:
Absmax Quantization
The absmax quantization technique scales weights based mostly on the utmost absolute worth within the tensor:
# Outline quantization features
def absmax_quantize(X):
scale = 100 / torch.max(torch.abs(X)) # Adjusted scale
X_quant = (scale * X).spherical()
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequantThis technique works by:
- Discovering the utmost absolute worth within the weight tensor
- Computing a scaling issue to suit values inside int8 vary
- Scaling and rounding the values
- Offering each quantized and dequantized variations
Key benefits:
- Easy implementation
- Good preservation of enormous values
- Symmetric quantization round zero
Zero-point Quantization
Zero-point quantization provides an offset to higher deal with uneven distributions:
def zeropoint_quantize(X):
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range
scale = 200 / x_range
zeropoint = (-scale * torch.min(X) - 128).spherical()
X_quant = torch.clip((X * scale + zeropoint).spherical(), -128, 127)
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequantOutput:
Utilizing machine: cudaThis technique:
- Calculates the complete vary of values
- Determines scale and zero-point parameters
- Applies scaling and shifting
- Clips values to make sure int8 bounds
Advantages:
- Higher dealing with of uneven distributions
- Improved illustration of near-zero values
- Typically leads to higher general accuracy
Loading and Getting ready the Mannequin
Let’s apply these quantization strategies to an actual mannequin. We’ll use GPT-2 as our instance:
# Load mannequin and tokenizer
model_id = 'gpt2'
mannequin = AutoModelForCausalLM.from_pretrained(model_id).to(machine)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Print mannequin measurement
print(f"Mannequin measurement: {mannequin.get_memory_footprint():,} bytes")Output:
Quantization Course of: Weights and Mannequin
Dive into making use of quantization strategies to each particular person weights and your entire mannequin. This step ensures lowered reminiscence utilization and computational effectivity whereas sustaining efficiency.
# Quantize and visualize weights
weights_abs_quant, _ = absmax_quantize(weights)
weights_zp_quant, _ = zeropoint_quantize(weights)
# Quantize your entire mannequin
model_abs = deepcopy(mannequin)
model_zp = deepcopy(mannequin)
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.information)
param.information = dequantized
for param in model_zp.parameters():
_, dequantized = zeropoint_quantize(param.information)
param.information = dequantizedVisualizing Quantized Weight Distributions
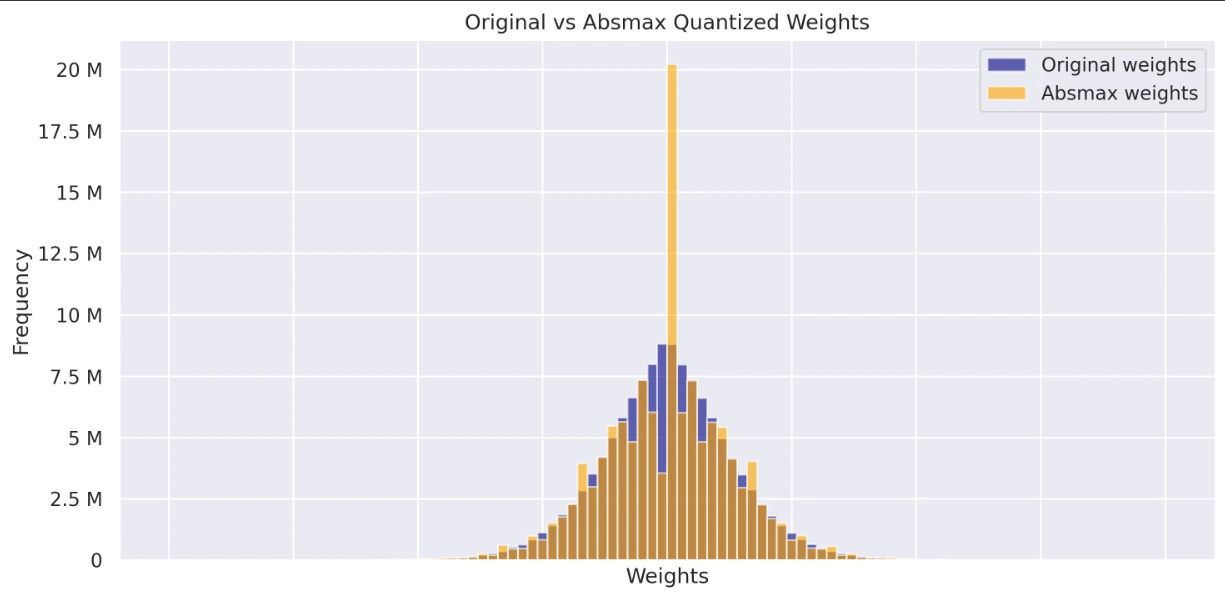
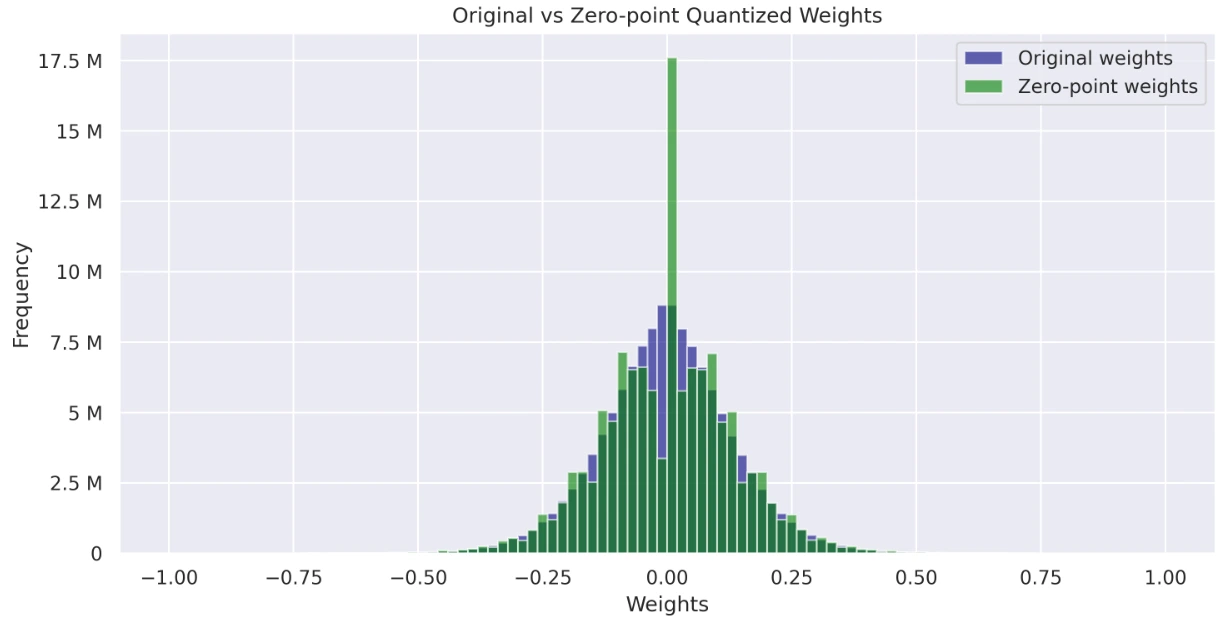
Visualize and examine the load distributions of the unique, absmax quantized, and zero-point quantized fashions. These histograms present insights into how quantization impacts weight values and their general distribution.
# Visualize histograms of weights
def visualize_histograms(original_weights, absmax_weights, zp_weights):
sns.set_theme(model="darkgrid")
fig, axs = plt.subplots(2, figsize=(10, 10), dpi=300, sharex=True)
axs[0].hist(original_weights, bins=100, alpha=0.6, label="Unique weights", shade="navy", vary=(-1, 1))
axs[0].hist(absmax_weights, bins=100, alpha=0.6, label="Absmax weights", shade="orange", vary=(-1, 1))
axs[1].hist(original_weights, bins=100, alpha=0.6, label="Unique weights", shade="navy", vary=(-1, 1))
axs[1].hist(zp_weights, bins=100, alpha=0.6, label="Zero-point weights", shade="inexperienced", vary=(-1, 1))
for ax in axs:
ax.legend()
ax.set_xlabel('Weights')
ax.set_ylabel('Frequency')
ax.yaxis.set_major_formatter(ticker.EngFormatter())
axs[0].set_title('Unique vs Absmax Quantized Weights')
axs[1].set_title('Unique vs Zero-point Quantized Weights')
plt.tight_layout()
plt.present()
# Flatten weights for visualization
original_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model.parameters()])
absmax_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model_abs.parameters()])
zp_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model_zp.parameters()])
visualize_histograms(original_weights, absmax_weights, zp_weights)The code features a complete visualization perform:
- Graph displaying Unique Weights vs Absmax Weights
- Graph displaying Unique Weights vs Zero-point Weights
Output:
Efficiency Analysis
Evaluating the influence of quantization on mannequin efficiency is crucial to make sure effectivity and accuracy. Let’s measure how nicely the quantized fashions carry out in comparison with the unique.
Textual content Technology
Discover how the quantized fashions generate textual content and examine the standard of outputs to the unique mannequin’s predictions.
def generate_text(mannequin, input_text, max_length=50):
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(machine)
output = mannequin.generate(inputs=input_ids,
max_length=max_length,
do_sample=True,
top_k=30,
pad_token_id=tokenizer.eos_token_id,
attention_mask=input_ids.new_ones(input_ids.form))
return tokenizer.decode(output[0], skip_special_tokens=True)
# Generate textual content with unique and quantized fashions
original_text = generate_text(mannequin, "The way forward for AI is")
absmax_text = generate_text(model_abs, "The way forward for AI is")
zp_text = generate_text(model_zp, "The way forward for AI is")
print(f"Unique mannequin:n{original_text}")
print("-" * 50)
print(f"Absmax mannequin:n{absmax_text}")
print("-" * 50)
print(f"Zeropoint mannequin:n{zp_text}")This code compares textual content era outputs from three fashions: the unique, an “absmax” quantized mannequin, and a “zeropoint” quantized mannequin. It makes use of a generate_text perform to generate textual content based mostly on an enter immediate, making use of sampling with a top-k worth of 30. Lastly, it prints the outcomes from all three fashions.
Output:

# Perplexity analysis
def calculate_perplexity(mannequin, textual content):
encodings = tokenizer(textual content, return_tensors="pt").to(machine)
input_ids = encodings.input_ids
with torch.no_grad():
outputs = mannequin(input_ids, labels=input_ids)
return torch.exp(outputs.loss)
long_text = "Synthetic intelligence is a transformative know-how that's reshaping industries."
ppl_original = calculate_perplexity(mannequin, long_text)
ppl_absmax = calculate_perplexity(model_abs, long_text)
ppl_zp = calculate_perplexity(model_zp, long_text)
print(f"nPerplexity (Unique): {ppl_original.merchandise():.2f}")
print(f"Perplexity (Absmax): {ppl_absmax.merchandise():.2f}")
print(f"Perplexity (Zero-point): {ppl_zp.merchandise():.2f}")The code calculates the perplexity (a measure of how nicely a mannequin predicts textual content) for a given enter utilizing three fashions: the unique, “absmax” quantized, and “zeropoint” quantized fashions. Decrease perplexity signifies higher efficiency. It prints the perplexity scores for comparability.
Output:

You can access colab link here.
Benefits of Weight Quantization
Beneath we’ll look into the benefits of weight quantization:
- Reminiscence Effectivity: Quantization reduces mannequin measurement by as much as 75%, enabling quicker loading and inference.
- Quicker Inference: Integer operations are quicker than floating-point operations, resulting in faster mannequin execution.
- Decrease Energy Consumption: Decreased reminiscence bandwidth and simplified computation result in power financial savings, important for edge units and cellular deployment.
- Deployment Flexibility: Smaller fashions are simpler to deploy on {hardware} with restricted assets (e.g., cellphones, embedded units).
- Minimal Efficiency Degradation: With the best quantization technique, fashions can retain most of their accuracy regardless of the lowered precision.
Conclusion
Weight quantization performs an important position in enhancing the effectivity of enormous language fashions, significantly in the case of deploying them on resource-constrained units. By changing high-precision weights to lower-precision integer representations, we are able to considerably scale back reminiscence utilization, enhance inference pace, and decrease energy consumption, all with out severely affecting the mannequin’s efficiency.
On this information, we explored two well-liked quantization strategies—absmax quantization and zero-point quantization—utilizing GPT-2 as a sensible instance. Each strategies demonstrated the power to scale back the mannequin’s reminiscence footprint and computational necessities whereas sustaining a excessive degree of accuracy in textual content era duties. Nonetheless, the zero-point quantization technique, with its uneven strategy, usually resulted in higher preservation of mannequin accuracy, particularly for non-symmetric weight distributions.
Key Takeaways
- Absmax Quantization is easier and works nicely for symmetric weight distributions, although it won’t seize uneven distributions as successfully as zero-point quantization.
- Zero-point Quantization gives a extra versatile strategy by introducing an offset to deal with uneven distributions, usually main to higher accuracy and a extra environment friendly illustration of weights.
- Quantization is crucial for deploying giant fashions in real-time functions the place computational assets are restricted.
- Regardless of the quantization course of lowering precision, it’s potential to take care of mannequin efficiency near the unique with correct tuning and quantization methods.
- Visualization strategies like histograms can present insights into how quantization impacts mannequin weights and the distribution of values within the tensors.
Continuously Requested Questions
A. Weight quantization reduces the precision of a mannequin’s weights, usually from 32-bit floating-point values to lower-precision integers (e.g., 8-bit integers), to save lots of reminiscence and computation whereas sustaining efficiency.
A. Whereas quantization reduces the mannequin’s reminiscence footprint and inference time, it might probably result in a slight degradation in accuracy. Nonetheless, if finished appropriately, the loss in accuracy is minimal.
A. Sure, quantization may be utilized to any neural community mannequin, together with language fashions, imaginative and prescient fashions, and different deep studying architectures.
A. You possibly can implement quantization by creating features to scale and around the mannequin’s weights, then apply them throughout all parameters. Libraries like PyTorch present native help for some quantization strategies, although customized implementations, as proven within the information, supply flexibility.
A. Weight quantization is best for giant fashions the place lowering reminiscence footprint and computation is crucial. Nonetheless, very small fashions could not profit as a lot from quantization.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.
![]()
My identify is Nilesh Dwivedi, and I am excited to hitch this vibrant neighborhood of bloggers and readers. I am at present in my first 12 months of BTech, specializing in Information Science and Synthetic Intelligence at IIIT Dharwad. I am obsessed with know-how and information science and searching ahead to write down extra blogs.
Login to proceed studying and revel in expert-curated content material.
")

