Google lately launched Gemini Embedding 2, its first natively multimodal embedding mannequin. This is a vital step ahead as a result of it brings textual content, photos, video, audio, and paperwork right into a single shared embedding area. As an alternative of working with separate fashions for every sort of knowledge, builders can now use one embedding mannequin throughout a number of modalities for retrieval, search, clustering, and classification.
That shift is highly effective in principle, nevertheless it turns into much more attention-grabbing when utilized to an actual undertaking. To discover what Gemini Embedding 2 can do in follow, I constructed a easy image-matching system that identifies which particular person in a question picture is most just like the saved photos.
Gemini Embedding 2 Key Options
Conventional embedding methods are sometimes designed for textual content alone. When you wished to construct a system that labored throughout photos, audio, or paperwork, you often needed to sew collectively a number of pipelines. Gemini Embedding 2 modifications by mapping various kinds of content material into one unified vector area.

In keeping with Google, Gemini Embedding 2 helps:
- Textual content with as much as 8192 enter tokens
- Pictures, with as much as 6 photos per request in PNG and JPEG format
- Video as much as 120 seconds in mp4 and mov
- Audio with no need transcription first
- PDF paperwork as much as 6 pages lengthy
It additionally helps interleaved multimodal enter, resembling picture plus textual content in a single request. This permits the mannequin to seize richer relationships between totally different varieties of knowledge.
One other vital characteristic is versatile output dimensionality via Matryoshka Illustration Studying. The default measurement is 3072 dimensions, however it will possibly scale all the way down to smaller sizes resembling 1536 or 768. This helps builders steadiness high quality, storage, and retrieval pace relying on the appliance.
Additionally Learn: 14 Highly effective Strategies Defining the Evolution of Embedding
Constructing an Picture Matching System Utilizing Gemini Embedding 2
The undertaking makes use of three folders inside a dataset listing:
dataset/
nitika/
vasu/
janvi/
Every folder incorporates a number of photos of 1 particular person. The purpose is easy:
- Learn all photos from the dataset
- Generate an embedding for every picture utilizing Gemini Embedding 2
- Retailer these embeddings in reminiscence and cache them regionally
- Take a question picture
- Generate its embedding
- Examine it with all saved picture embeddings utilizing cosine similarity
- Return the highest matching photos and predict the particular person title
This can be a sturdy instance of how Gemini Embedding 2 can be utilized for image-based retrieval and light-weight classification.
The perfect a part of this undertaking is that it doesn’t require a full deep studying coaching pipeline. There is no such thing as a customized CNN coaching, no fine-tuning, and no annotation-heavy workflow. As an alternative, the system depends on the embedding mannequin as a semantic characteristic extractor.
That makes growth a lot sooner.
Since Gemini Embedding 2 is natively multimodal, the identical undertaking design can later be prolonged past photos. For instance:
- Matching a spoken audio clip to an individual profile
- Trying to find a related PDF from a picture
- Retrieving a video section from a textual content question
- Evaluating combined picture and textual content descriptions in a single embedding area
On this sense, the present undertaking is an easy entry level into a much wider multimodal retrieval structure.
Gemini Embedding 2 API Utilization
Google gives the Gemini Embedding 2 mannequin via the Gemini API and Vertex AI. The embedding name is made via the embed_content technique.
A multimodal instance from Google seems like this:
from google import genai
from google.genai import sorts
shopper = genai.Consumer()
with open("instance.png", "rb") as f:
image_bytes = f.learn()
with open("pattern.mp3", "rb") as f:
audio_bytes = f.learn()
outcome = shopper.fashions.embed_content(
mannequin="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(outcome.embeddings) For my undertaking, I solely wanted the picture a part of this workflow. As an alternative of sending textual content, picture, and audio collectively, I used a single picture per request and generated its embedding.
Venture Implementation
The undertaking begins by loading the Gemini API key from a .env file and making a shopper:
from dotenv import load_dotenv
import os
from google import genai
load_dotenv()
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
shopper = genai.Consumer(api_key=GEMINI_API_KEY) Then I outlined helper features for picture validation, MIME sort detection, normalization, cosine similarity, and picture show.
The primary embedding operate reads the picture bytes and sends them to Gemini Embedding 2:
def embed_image(image_path):
image_path = Path(image_path)
mime_type = guess_mime_type(image_path)
with open(image_path, "rb") as f:
image_bytes = f.learn()
outcome = shopper.fashions.embed_content(
mannequin="gemini-embedding-2-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type=mime_type,
)
],
config=sorts.EmbedContentConfig(
output_dimensionality=3072
)
)
emb = np.array(outcome.embeddings[0].values, dtype=np.float32)
return normalize(emb) This operate is the core of the whole pipeline. It turns every picture right into a 3072-dimensional vector illustration.
Constructing the Dataset Embedding Database
The following step is to stroll via the dataset folder, learn all photos for every particular person, and embed them one after the other.
Every embedded picture is saved as a dictionary containing:
- the particular person label
- the file path
- the embedding vector
To keep away from recomputing embeddings each time, I cached them into an area pickle file:
def build_embeddings_db(dataset, cache_file="image_embeddings_cache.pkl", force_rebuild=False):
cache_path = Path(cache_file)
if cache_path.exists() and never force_rebuild:
with open(cache_path, "rb") as f:
embeddings_db = pickle.load(f)
return embeddings_db
embeddings_db = []
for merchandise in dataset:
emb = embed_image(merchandise["path"])
embeddings_db.append({
"label": merchandise["label"],
"path": merchandise["path"],
"embedding": emb
})
with open(cache_path, "wb") as f:
pickle.dump(embeddings_db, f)
return embeddings_dbThis makes the pocket book rather more environment friendly as a result of embeddings are solely generated as soon as until the dataset modifications.
Matching a Question Picture
As soon as the dataset embeddings are prepared, the following step is to check the system with a brand new question picture.
The question picture is embedded utilizing the identical operate. Then its embedding is in comparison with all saved embeddings utilizing cosine similarity.
def find_best_matches(query_image_path, top_k=5):
query_emb = embed_image(query_image_path)
outcomes = []
for merchandise in embeddings_db:
rating = cosine_similarity(query_emb, merchandise["embedding"])
outcomes.append({
"label": merchandise["label"],
"path": merchandise["path"],
"rating": rating
})
outcomes.kind(key=lambda x: x["score"], reverse=True)
return outcomes[:top_k] This operate returns the highest matching dataset photos.
To foretell the ultimate particular person label, I used top-k voting:
def predict_person(query_image_path, top_k=5):
matches = find_best_matches(query_image_path, top_k=top_k)
labels = [m["label"] for m in matches]
predicted_label = Counter(labels).most_common(1)[0][0]
return predicted_label, matches That is extra steady than counting on a single nearest picture.
Testing the Venture
Within the undertaking, I examined question photos resembling:
Instance 1:
query_image = "Nitika_Test_Image.jpeg"
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery picture:")
show_image(query_image, title="Question Picture")
print("Predicted particular person:", predicted_person)
print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | rating={match['score']:.4f} | path={match['path']}")
show_image(match["path"], title=f"Rank {i} | {match['label']} | rating={match['score']:.4f}")
print("nBest match:")
print(matches[0])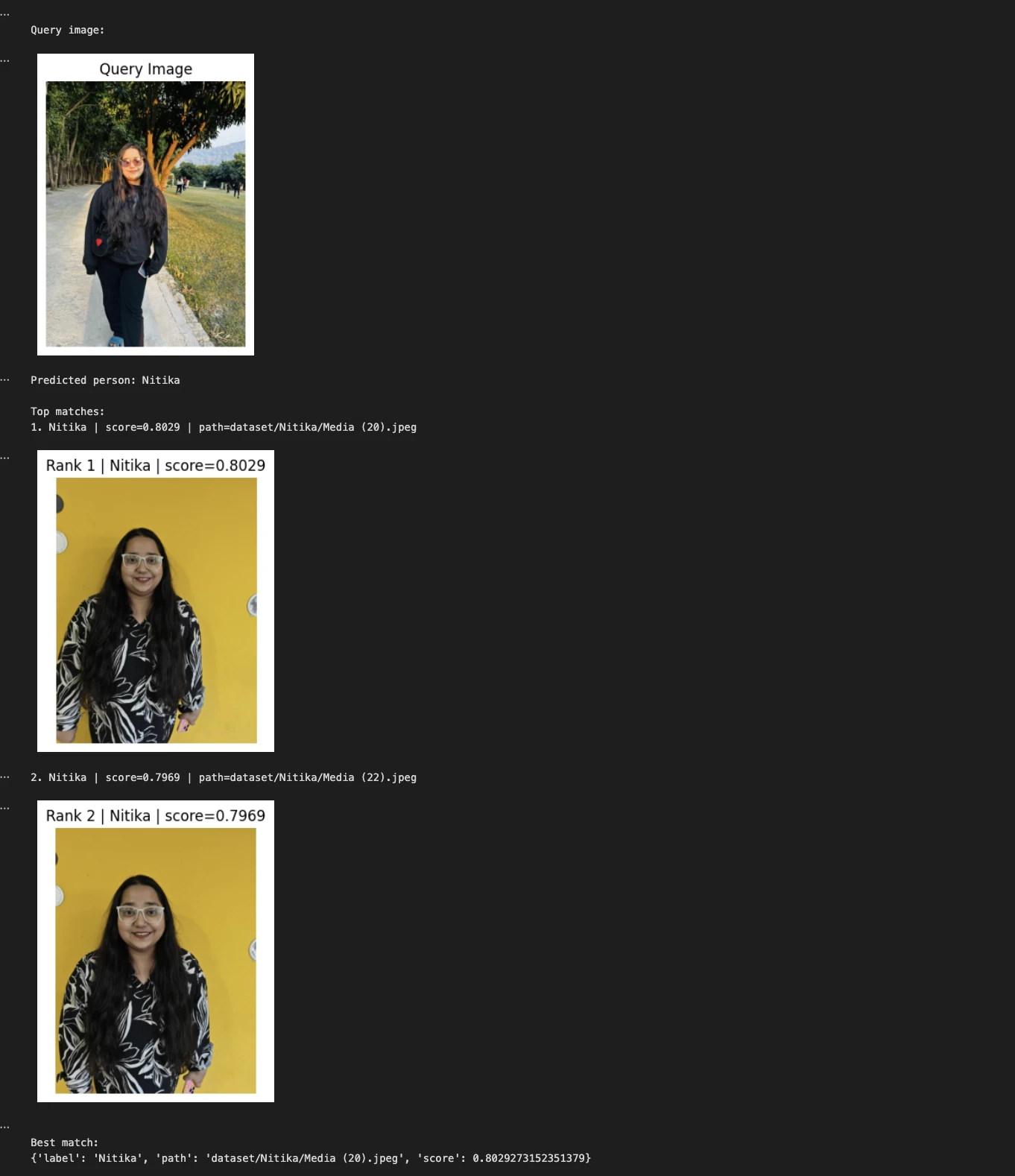
Instance 2:
query_image = "/Customers/janvi/Downloads/Him.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery picture:") show_image(query_image, title="Question Picture")
print("Predicted particular person:", predicted_person) print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | rating={match['score']:.4f} | path={match['path']}") show_image(match["path"], title=f"Rank {i} | {match['label']} | rating={match['score']:.4f}")
print("nBest match:") print(matches[0])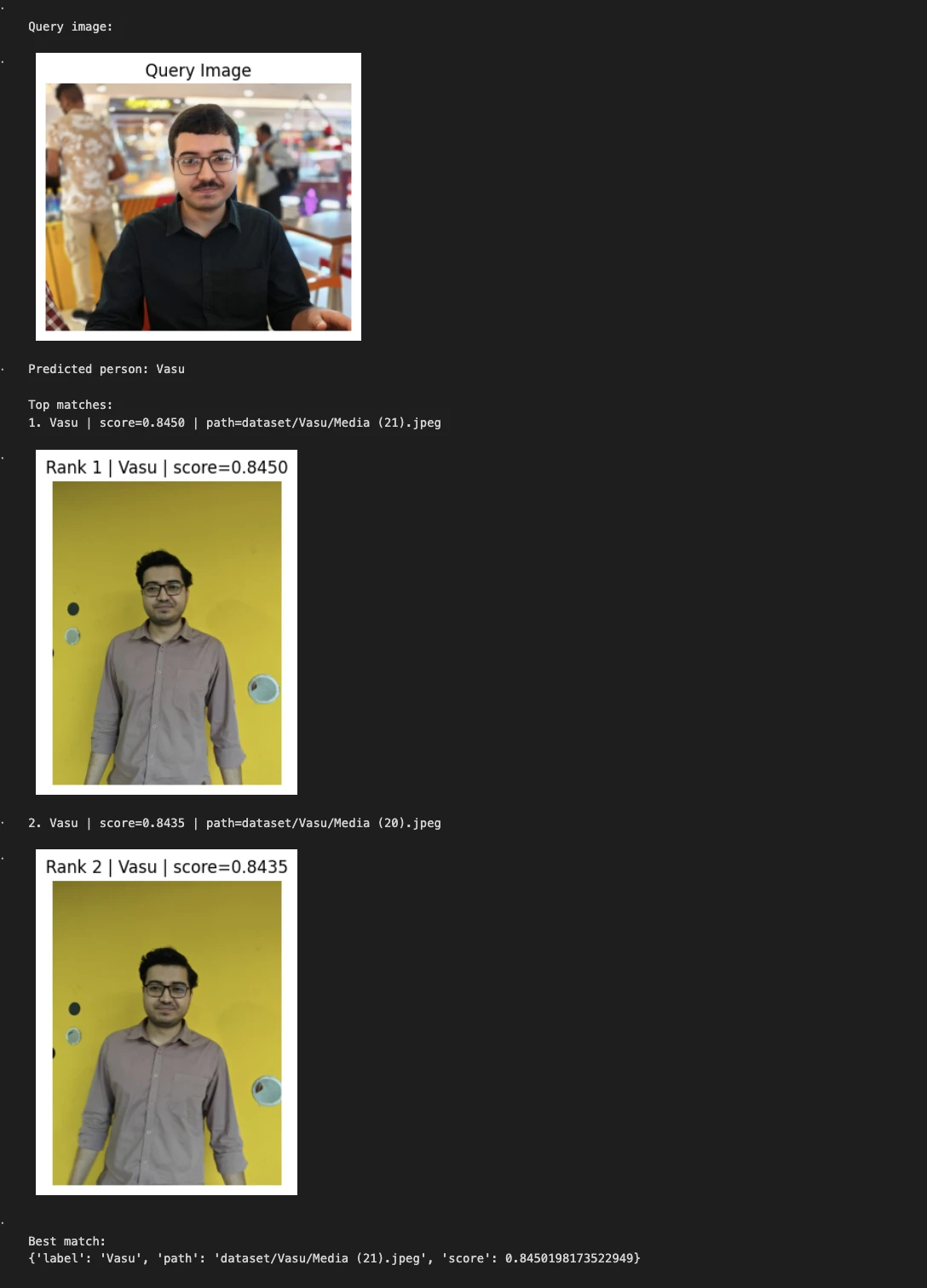
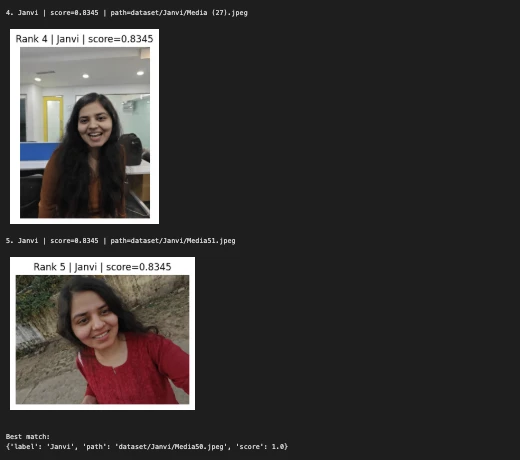
third Instance:
query_image = "/Customers/janvi/Downloads/Nerd.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=5)
print("nQuery picture:")
show_image(query_image, title="Question Picture")
print("Predicted particular person:", predicted_person)
print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | rating={match['score']:.4f} | path={match['path']}")
show_image(match["path"], title=f"Rank {i} | {match['label']} | rating={match['score']:.4f}")
print("nBest match:")
print(matches[0])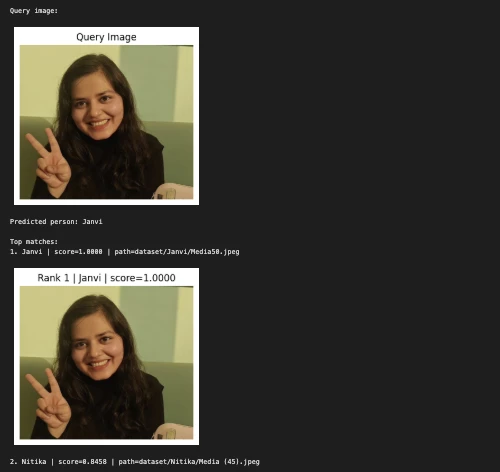
The pocket book then displayed:
- the question picture
- the anticipated particular person label
- the highest matching photos from the dataset
- the cosine similarity rating for every match
This makes the system straightforward to examine visually and helps confirm whether or not the embedding-based retrieval is working accurately.
My Expertise of Utilizing Gemini Embedding 2
This undertaking could also be easy, nevertheless it clearly demonstrates the sensible worth of Gemini Embedding 2.
First, it reveals that embeddings can be utilized immediately for picture retrieval with out coaching a separate classification mannequin.
Second, it reveals how a shared embedding area can simplify actual functions. Though this model solely makes use of photos, the identical structure can later be prolonged to textual content, audio, video, and doc retrieval.
Third, it highlights how trendy multimodal embeddings scale back the necessity for complicated preprocessing pipelines. As an alternative of manually extracting handcrafted options or constructing a mannequin from scratch, builders can use the embedding mannequin as a general-purpose semantic spine.
Strengths of This Strategy
There are a number of causes this strategy works effectively for a prototype:
- Little or no coaching overhead
- Easy implementation in a pocket book
- Straightforward to increase
- Quick experimentation
- Human-readable outcomes via high match visualization
- Works naturally with similarity search
It’s particularly helpful for small-scale picture matching duties the place you desire a clear proof of idea.
Limitations
On the similar time, that is nonetheless a light-weight demo and never a manufacturing biometric system.
A number of limitations are value noting:
- Efficiency depends upon picture high quality, lighting, background, and pose
- Extra photos per particular person often enhance robustness
- Comparable-looking individuals could produce nearer embeddings
- The present pipeline doesn’t embrace an unknown-person threshold
- A full analysis set could be wanted for severe benchmarking
These should not failures of Gemini Embedding 2. They’re regular issues for any picture matching system.
Conclusion
Gemini Embedding 2 marks an vital shift in how builders can work with multimodal information. As an alternative of constructing separate pipelines for textual content, picture, audio, video, and paperwork, we now have a mannequin designed to signify all of them in a unified semantic area.
My image-matching undertaking is a small however helpful instance of this concept in follow. By embedding photos of three identified individuals and evaluating a question picture via cosine similarity, I used to be in a position to construct a clear retrieval and classification workflow with little or no code.
That’s the actual promise of Gemini Embedding 2. It’s not solely a brand new mannequin announcement. It’s a sensible constructing block for multimodal methods which are simpler to design, simpler to scale, and far nearer to real-world information.
Steadily Requested Questions
A. It’s Google’s multimodal embedding mannequin that maps textual content, photos, audio, video, and paperwork into one shared vector area for search, retrieval, clustering, and classification.
A. It embeds dataset photos, compares a question picture utilizing cosine similarity, and predicts the particular person primarily based on the closest matching embeddings.
A. It acts as a semantic characteristic extractor, permitting picture matching with out constructing or coaching a separate deep studying classification mannequin.
![]()
Hello, I’m Janvi, a passionate information science fanatic at present working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we are able to extract significant insights from complicated datasets.
Login to proceed studying and revel in expert-curated content material.


