
ShengShu Technology has unveiled Motubrain, a world motion mannequin that replaces a number of task-specific methods with a single, unified mannequin that features as a robotic mind for the bodily world.
ShenShu describes Motubrain as one mind that provides infinite potentialities for robotic intelligence.
Rating extremely on each WorldArena and RoboTwin 2.0, two of the sphere’s most rigorous benchmarks in embodied world fashions, Motubrain marks a decisive shift in an trade the place robotic methods are sometimes constructed from task-specific or specialised methods.
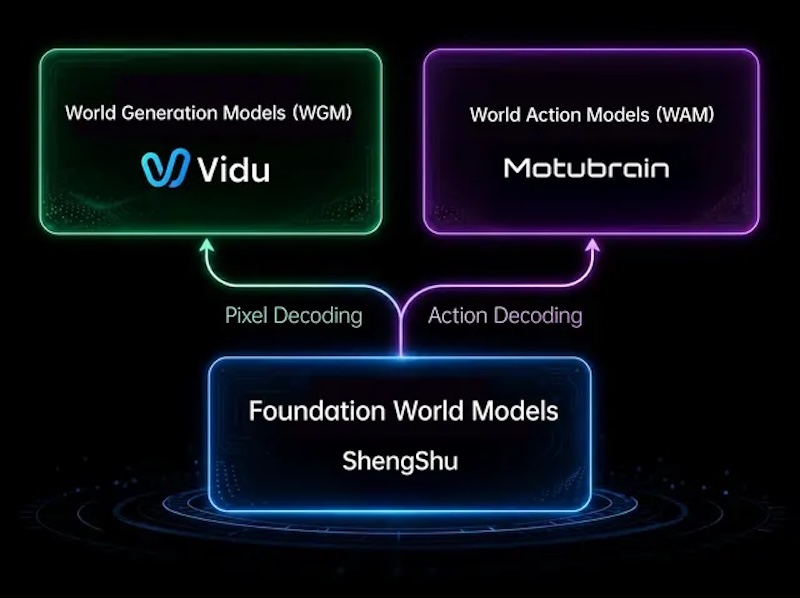
Greatest recognized for its main video mannequin Vidu, ShengShu Expertise and its developments in generative video for robotics earmarks an trade first. Generative video has laid the inspiration for simulating robots in real-world environments at scale.
Motubrain builds on this by turning these simulations into motion, by enabling robots to study from numerous, large-scale pre-training knowledge whereas lowering reliance on conventional bodily knowledge assortment.
“A real world mannequin should have the ability to construct a unified illustration of the actual world and predict the way it evolves,” mentioned Jun Zhu, founding father of ShengShu Expertise.
“Video is a essential basis of that intelligence as a result of it naturally captures time, area, movement, causality, and bodily dynamics at scale.
“We imagine common world fashions shouldn’t be constructed as stitched-together modules, however as a unified structure that brings collectively notion, reasoning, prediction, era, and motion in a single system. That’s what can in the end bridge the digital world and the bodily world.”
Among the many high performers in embodied AI
Motubrain has delivered top-tier efficiency on main embodied AI benchmarks. Ranked among the many trade’s greatest fashions for robotic notion, anticipation, and planning within the bodily world, Motubrain achieved a 63.77 EWM Rating on WorldArena.
It has additionally been acknowledged as one of many strongest performers on RoboTwin 2.0, scoring a median of 96.0 throughout 50 predetermined duties, and stays the one mannequin to exceed 95.0 in randomized environments.
The structure behind the breakthrough
Motubrain’s core breakthrough is unifying the “seen world” and the “actions to take” inside a single mannequin, and it’s constructed on 4 core rules that collectively redefine what an embodied AI mannequin for coaching robots could be:
- One Mind, Many Abilities: A unified mannequin that may deal with a variety of duties and will get smarter and stronger as job selection will increase. Coaching every talent one after the other is not required, and in contrast to typical fashions, the broader the vary of complicated duties it handles directly, Motubrain’s success fee and reliability with multi-tasking will increase.
- One Mind, Common Throughout Robots: Motubrain isn’t constructed for a single robotic mannequin. It’s designed to be a common mind that may energy many sorts of robots. This breaks the previous “one robotic, one mannequin” sample. And as extra robotic varieties, actual‑world situations, and knowledge be a part of the ecosystem, Motubrain retains getting smarter, which in flip helps each robotic within the community carry out higher.
- One Mind, Finish-to-Finish: Motubrain learns whole job sequences instantly. It could deal with complicated, multi‑step duties involving as much as 10 atomic actions, also referred to as the smallest unit of motion in robotics, far past the everyday 2-3 atomic actions. So the robotic not sees remoted actions; it sees an entire, significant job from begin to end.
- One Mind, Capable of Anticipate: Predicts the world whereas driving motion. Environmental change, job development, and execution are processed collectively inside one mannequin, not assembled from separate subsystems.
To ship this, Motubrain is constructed on a Unified Multimodal Mannequin that treats video and motion as two steady modalities to be realized collectively.
A single coaching run offers it 5 capabilities directly: vision-language-action management (VLA), world modelling, video era, inverse dynamics modelling (IDM), and joint video-action prediction.
A 3-stream Combination-of-Transformers (MoT) then brings video, motion, and language collectively by drawing on the strengths of present pretrained fashions, enabling Motubrain to grasp environments, observe language directions, predict what occurs subsequent, and generate actions all on the identical time.
In contrast to methods that chain collectively separate notion, planning, and management modules, Motbrain processes the complete loop.
Motbrain learns from a far broader vary of knowledge than typical AI fashions that prepare robots, together with unlabelled video, job recordings with out language annotations, and knowledge from totally different robotic embodiments.
A proprietary latent motion framework extracts bodily movement instantly from large-scale video, together with human footage, simulation knowledge, and multi-robot job trajectories, with out requiring the information to be labelled or tagged to point particular actions.
This broader studying paradigm interprets into robust scaling conduct. In task-scaling evaluations, Motubrain’s common success fee continued to rise because the variety of coaching duties elevated, reaching roughly 92 % at 50 duties, whereas Pi-0.5 declined to roughly 68 % over the identical vary.
In data-scaling evaluations, Motubrain additionally maintained a transparent benefit because the variety of coaching episodes elevated, attaining about 92 % common success at 27,500 episodes, in contrast with roughly 85 % for Motus and 68 % for Pi-0.5.
A 3-stage pipeline constructed on a six-layer knowledge pyramid lets Motubrain generalise abilities throughout environments and robotic varieties whereas remaining exact sufficient for fine-grained deployment situations.
Motubrain understands what is going on round it, anticipates what could occur subsequent, and responds in actual time. In real-world assessments, robots skilled with Motubrain have carried out full, multi-step duties with a degree of adaptability past most typical robotic methods.
For instance, they will insert flowers right into a vase below altering circumstances and use each arms independently for various objectives.
Most notably, Motubrain-trained robots show a exceptional potential to grasp and predict outcomes throughout execution: when a ladle comes up empty whereas scooping, they will recognise that nothing has been collected and robotically try the scooping motion once more, regardless of by no means being skilled on retry knowledge.
This marks the shift from robots that merely execute duties to robots that actually full them.
Coaching the subsequent era of robots
Motubrain isn’t a analysis mannequin awaiting commercialisation; it’s operational. A number of main robotics firms are already utilizing Motubrain in energetic robotic coaching packages, deploying its cross-embodiment, multi-skill capabilities on actual {hardware} throughout industrial, business, and residential environments.
To additional improve real-world efficiency, ShengShu has partnered with Astribot, SimpleAI, and Anyverse Dynamics to advance a general-purpose embodied AI mind, specializing in basis mannequin evolution, multimodal knowledge integration, sturdy knowledge infrastructure, and full-stack hardware-software optimisation.
Connecting the dots: Alibaba’s funding and Motubrain
Motubrain is ShengShu’s subsequent strategic pillar, alongside Vidu, the corporate’s flagship generative video platform, which its latest Vidu Q3 ranked No.1 within the first international Reference-to-Video leaderboard launched by SuperClue.
The 2 merchandise are distinct in software however steady on the basis: the identical world mannequin expertise that makes Vidu one of many world’s main video era methods offers Motubrain its capability to foretell and act within the bodily world. The place Vidu generates the world, Motubrain acts in it.
Backed by a $293 million Sequence B led by Alibaba Cloud and with traders together with the China Web Funding Fund, TAL Schooling Group, Baidu Ventures, and Luminous Ventures, ShengShu enters the bodily AI period as a pacesetter, attaining profitable dwell deployments and boasting the very best benchmarks for its distinctive potential to each deeply perceive and successfully act upon its duties.


