
Machine studying is behind most of the applied sciences that affect our lives immediately, starting from suggestion programs to fraud detection. Nonetheless, the potential to assemble fashions that really handle our issues includes greater than programming expertise. Due to this fact, a profitable machine studying growth hinges on bridging technical work with sensible want and making certain that options generate measurable worth. On this article, we are going to focus on ideas for constructing ML fashions that create real-world influence. This contains setting clear goals, having high-quality information, planning for deployment, and sustaining fashions for sustained influence.
Core Rules for Constructing Actual-World ML Fashions
Now, from this part onwards, we’ll lay out the basic ideas that decide whether or not or not ML fashions carry out properly in real-world situations. All main matters, together with give attention to information high quality, choosing the proper algorithm, deployment, post-deployment monitoring, equity of the working mannequin, collaboration, and steady enchancment, will probably be mentioned right here. By adhering to those ideas, one can arrive at helpful, reliable, and maintainable options.
Good Knowledge Beats Fancy Algorithms
Even extremely refined algorithms require high-quality information. The saying goes: “rubbish in, rubbish out.” When you feed the mannequin messy or biased information, you’ll obtain messy or biased outcomes. Because the consultants say, “good information will at all times outperform cool algorithms.” ML successes begin with a robust information technique, as a result of “a machine studying mannequin is just nearly as good as the info it’s educated on.” Merely put, a clear and well-labeled dataset will extra usually outperform a classy mannequin constructed on flawed information.
In observe, this implies cleansing and validating information earlier than modeling. For instance, the California housing dataset (through sklearn.datasets.fetch_california_housing) accommodates 20,640 samples and eight options (median earnings, home age, and so forth.). We load it right into a DataFrame and add the worth goal:
from sklearn.datasets import fetch_california_housing
import pandas as pd
import seaborn as sns
california = fetch_california_housing()
dataset = pd.DataFrame(california.information, columns=california.feature_names)
dataset['price'] = california.goal
print(dataset.head())
sns.pairplot(dataset)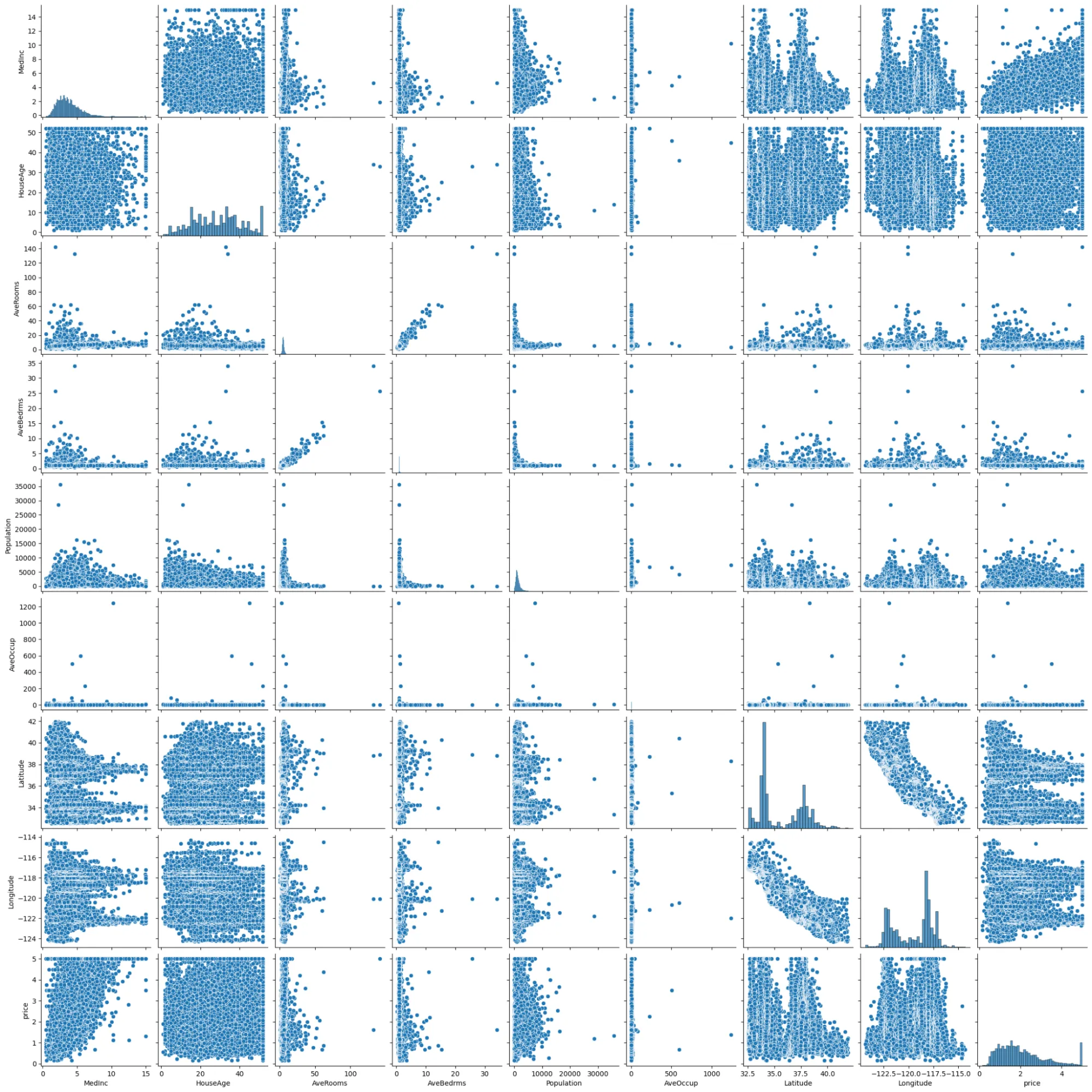
This offers the primary rows of our information with all numeric options and the goal value. We then examine and clear it: for instance, test for lacking values or outliers with data and describe strategies:
print(dataset.data())
print(dataset.isnull().sum())
print(dataset.describe())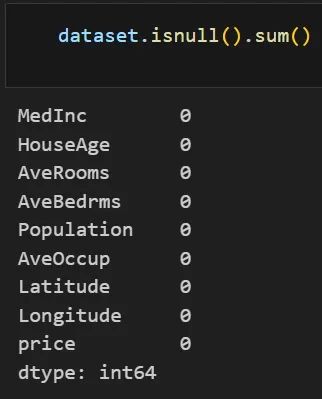
These summaries verify no lacking values and reveal the info ranges. As an illustration, describe() reveals the inhabitants and earnings ranges.
sns.regplot(x="AveBedrms",y="value",information=dataset)
plt.xlabel("Avg. no. of Mattress rooms")
plt.ylabel("Home Value")
plt.present()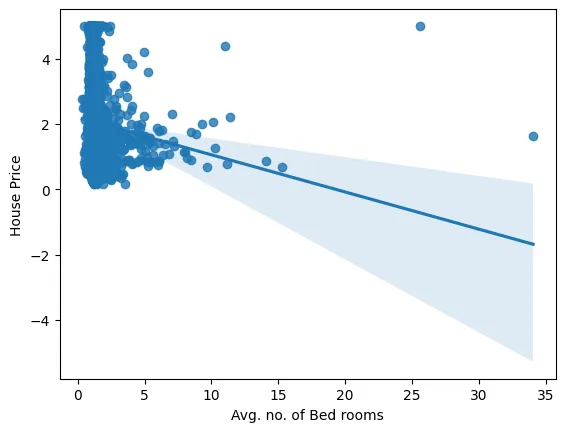
This plot reveals the variation of the home value with the variety of bedrooms.
In sensible phrases, this implies:
- Determine and proper any lacking values, outliers, and measurement errors earlier than modeling.
- Clear and label the info correctly and double-check every little thing in order that bias or noise doesn’t creep in.
- Herald information from different sources or go for artificial examples to cowl these uncommon instances.
Deal with the Drawback First, Not the Mannequin
The commonest mistake in machine studying tasks is specializing in a specific approach earlier than understanding what you’re attempting to resolve. Due to this fact, earlier than embarking on modeling, it’s essential to realize a complete understanding of the enterprise surroundings and person necessities. This includes involving stakeholders from the start, fosters alignment, and ensures shared expectations.
In sensible phrases, this implies:
- Determine enterprise selections and outcomes that may present route for the challenge, e.g,. mortgage approval, pricing technique.
- Measure success by way of quantifiable enterprise metrics as an alternative of technical indicators.
- Gather area information and set KPIs like income acquire or error tolerance accordingly.
- Sketching the workflow, right here, our ML pipeline feeds into an internet app utilized by actual property analysts, so we ensured our enter/output schema matches that app.
In code phrases, it interprets to choosing the function set and analysis standards earlier than engaged on the algorithm. As an illustration, we’d resolve to exclude much less essential options or to prioritize minimizing overestimation errors.
Measure What Actually Issues
The success of your fashions needs to be evaluated on the truth of their enterprise outcomes, not their technical scorecard. Recall, precision, or RMSE may not imply a lot if it doesn’t result in improved income, effectivity, or enhance the satisfaction amongst your customers. Due to this fact, at all times set mannequin success in opposition to KPI’s that the stakeholders worth.
For instance, if now we have a threshold-based determination (purchase vs. skip a home), we might simulate the mannequin’s accuracy on that call process. In code, we compute normal regression metrics however interpret them in context:
from sklearn.metrics import mean_squared_error, r2_score
pred = mannequin.predict(X_test)
print("Check RMSE:", np.sqrt(mean_squared_error(y_test, pred)))
print("Check R^2:", r2_score(y_test, pred))In sensible phrases, this implies:
- Outline metrics in opposition to precise enterprise outcomes similar to income, financial savings, or engagement.
- Don’t simply depend on technical measures similar to precision or RMSE.
- Articulate your ends in enterprise vernacular that stakeholders perceive.
- Present precise worth utilizing measures like ROI, conversion charges, or elevate charts.
Begin Easy, Add Complexity Later
Many machine studying tasks fail attributable to overcomplicating fashions too early within the course of. Establishing a easy baseline provides perspective, reduces overfitting, and simplifies debugging.
So, we start modeling with a easy baseline (e.g., linear regression) and solely add complexity when it clearly helps. This avoids overfitting and retains growth agile. In our pocket book, after scaling options, we first match a plain linear regression:
from sklearn.linear_model import LinearRegression
mannequin = LinearRegression()
mannequin.match(X_train, y_train)
reg_pred = mannequin.predict(X_test)
print("Linear mannequin R^2:", r2_score(y_test, reg_pred))
# 0.5957702326061665
LinearRegression i ?
LinearRegression()This establishes a efficiency benchmark. If this easy mannequin meets necessities, no must complicate issues. In our case, we then tried including polynomial options to see if it reduces error:
from sklearn.preprocessing import PolynomialFeatures
train_rmse_errors=[]
test_rmse_errors=[]
train_r2_score=[]
test_r2_score=[]
for d in vary(2,3):
polynomial_converter = PolynomialFeatures(diploma=d,include_bias=False)
poly_features = polynomial_converter.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(poly_features, y,test_size=0.3, random_state=42)
mannequin = LinearRegression(fit_intercept=True)
mannequin.match(X_train,y_train)
train_pred = mannequin.predict(X_train)
test_pred = mannequin.predict(X_test)
train_RMSE = np.sqrt(mean_squared_error(y_train,train_pred))
test_RMSE = np.sqrt(mean_squared_error(y_test,test_pred))
train_r2= r2_score(y_train,train_pred)
test_r2 = r2_score(y_test,test_pred)
train_rmse_errors.append(train_RMSE)
test_rmse_errors.append(test_RMSE)
train_r2_score.append(train_r2)
test_r2_score.append(test_r2)
# highest take a look at r^2 rating:
highest_r2_score=max(test_r2_score)
highest_r2_score
# 0.6533650019044048In our case, the polynomial regression outperformed the Linear regression, subsequently we’ll use it for making the take a look at predictions. So, earlier than that, we’ll save the mannequin.
with open('scaling.pkl', 'wb') as f:
pickle.dump(scaler, f)
with open('polynomial_converter.pkl', 'wb') as f:
pickle.dump(polynomial_converter, f)
print("Scaler and polynomial options converter saved efficiently!")
# Scaler and polynomial options converter saved efficiently!In sensible phrases, this implies:
- Begin with baseline fashions (like linear regression or tree-based fashions).
- Baselines present a measure of enchancment for complicated fashions.
- Add complexity to fashions solely when measurable modifications are returned.
- Incrementally design fashions to make sure debugging is at all times easy.
Plan for Deployment from the Begin
Profitable machine studying tasks should not simply when it comes to constructing fashions and saving one of the best weight recordsdata, but additionally in getting them into manufacturing. It is advisable be occupied with essential constraints from the start, together with latency, scalability, and safety. Having a deployment technique from the start simplifies the deployment course of and improves planning for integration and testing.
So we design with deployment in thoughts. In our challenge, we knew from Day 1 that the mannequin would energy an internet app (a Flask service). We subsequently:
- Ensured the info preprocessing is serializable (we saved our StandardScaler and PolynomialFeatures objects with pickle).
- Select mannequin codecs suitable with our infrastructure (we saved the educated regression through pickle, too).
- Hold latency in thoughts: we used a light-weight linear mannequin relatively than a big ensemble to satisfy real-time wants.
import pickle
from flask import Flask, request, jsonify
app = Flask(__name__)
mannequin = pickle.load(open("poly_regmodel.pkl", "rb"))
scaler = pickle.load(open("scaling.pkl", "rb"))
poly_converter = pickle.load(open("polynomial_converter.pkl", "rb"))
@app.route('/predict_api', strategies=['POST'])
def predict_api():
information = request.json['data']
inp = np.array(listing(information.values())).reshape(1, -1)
scaled = scaler.remodel(inp)
options = poly_converter.remodel(scaled)
output = mannequin.predict(options)
return jsonify(output[0])This snippet reveals a production-ready prediction pipeline. It hundreds the preprocessing and mannequin, accepts JSON enter, and returns a value prediction. By occupied with APIs, model management, and reproducibility from the beginning. So, we will keep away from the last-minute integration complications.
In sensible phrases, this implies:
- Clearly determine at first what deployment wants you might have when it comes to scalability, latency, and useful resource limits.
- Incorporate model management, automated testing, and containerization in your mannequin growth workflow.
- Think about how and when to maneuver information and knowledge round, your integration factors, and the way errors will probably be dealt with as a lot as doable at first.
- Work with engineering or DevOps groups from the beginning.
Hold an Eye on Fashions After Launch
Deployment shouldn’t be the tip of the road; fashions can drift or degrade over time as information and environments change. Ongoing monitoring is a key part of mannequin reliability and influence. It’s best to look ahead to drift, anomalies, or drops in accuracy, and it’s best to attempt to tie mannequin efficiency to enterprise outcomes. Ensuring you recurrently retrain fashions and log correctly is essential to make sure that fashions will proceed to be correct, compliant, and related to the true world, all through time.
We additionally plan computerized retraining triggers: e.g., if the distribution of inputs or mannequin error modifications considerably, the system flags for re-training. Whereas we didn’t implement a full monitoring stack right here, we be aware that this precept means establishing ongoing analysis. As an illustration:
# (Pseudo-code for monitoring loop)
new_data = load_recent_data()
preds = mannequin.predict(poly_converter.remodel(scaler.remodel(new_data[features])))
error = np.sqrt(mean_squared_error(new_data['price'], preds))
if error > threshold:
alert_team()In sensible phrases, this implies:
- Use dashboards to watch enter information distributions and output metrics.
- Think about monitoring technical accuracy measures parallel with enterprise KPIs.
- Configure alerts to do preliminary monitoring, detect anomalies, or information drift.
- Retrain and replace fashions recurrently to make sure you are sustaining efficiency.
Hold Enhancing and Updating
Machine studying is rarely completed, i.e, the info, instruments, and enterprise wants change consistently. Due to this fact, ongoing studying and iteration are essentially processes that allow our fashions to stay correct and related. Iterative updates, error evaluation, exploratory studying of latest algorithms, and increasing talent units give groups a greater probability of sustaining peak efficiency.
In sensible phrases, this implies:
- Schedule common retraining with incremental information.
- Gather suggestions and evaluation of errors to enhance fashions.
- Experiment with newer algorithms, instruments, or options that enhance worth.
- Spend money on progressive coaching to strengthen your crew’s ML information.
Construct Truthful and Explainable Fashions
Equity and transparency are important when fashions can affect individuals’s every day lives or work. Knowledge and algorithmic bias can result in detrimental results, whereas black-box fashions that fail to supply explainability can lose the belief of customers. By working to make sure organizations are honest and current explainability, organizations are constructing belief, assembly moral obligations, and offering clear rationales about mannequin predictions. Particularly in the case of delicate matters like healthcare, employment, and finance.
In sensible phrases, this implies:
- Examine the efficiency of your mannequin throughout teams (e.g., by gender, ethnicity, and so forth.) to determine any disparities.
- Be intentional about incorporating equity methods, similar to re-weighting or adversarial debiasing.
- Use explainability instruments (e.g., SHAP, LIME, and so forth.) to have the ability to clarify predictions.
- Set up various groups and make your fashions clear together with your audiences.
Notice: For the whole model of the code, you possibly can go to this GitHub repository.
Conclusion
An efficient ML system builds readability, simplicity, collaboration, and ongoing flexibility. One ought to begin with targets which might be clear, work with good high quality information, and take into consideration deployment as early as doable. Ongoing retraining and various stakeholder views and views will solely enhance your outcomes. Along with accountability and clear processes, organizations can implement machine studying options which might be adequate, reliable, clear, and responsive over time.
Regularly Requested Questions
A. As a result of poor information results in poor outcomes. Clear, unbiased, and well-labeled datasets persistently outperform fancy fashions educated on flawed information.
A. By enterprise outcomes like income, financial savings, or person satisfaction, not simply technical metrics similar to RMSE or precision.
A. Easy fashions provide you with a baseline, are simpler to debug, and infrequently meet necessities with out overcomplicating the answer.
A. Think about scalability, latency, safety, model management, and integration from the begin to keep away from last-minute manufacturing points.
A. As a result of information modifications over time. Monitoring helps detect drift, keep accuracy, and make sure the mannequin stays related and dependable.
![]()
Good day! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am desirous to contribute my expertise in a collaborative surroundings whereas persevering with to study and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.

